Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniero de datos especializado en ETL Pipelines, Databricks, Azure y Power BI
Hola, soy un consultor de ingeniería de datos con más de 5 años creando pipelines de datos en producción en Databricks.
He diseñado cargas de trabajo reales en Databricks en producción, incluyendo una plataforma de datos de clientes que procesa conjuntos de datos a gran escala con PySpark, Delta Live Tables y arquitectura medallion. Trabajo en Databricks a diario, no solo como una palabra de moda.
Lo que construiré para ti:
Por qué trabajar conmigo:
Pila tecnológica:
Antes de ordenar:
Envíame un mensaje con todos tus requisitos.

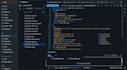
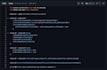
Plataforma de destino:
Databricks Lakehouse
Herramientas y plataformas:
Otros


