Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Científico de datos, ingeniero de soluciones de IA, especialista en IA agentic
¿Los datos desordenados te están frenando? La mayoría de los proyectos de Data Science fracasan por la mala calidad de los datos. Estoy aquí para ayudarte. Ofrezco servicios expertos de limpieza de datos, análisis exploratorio de datos (EDA) y ingeniería de características para asegurar que tus datos sean precisos, reveladores y estén listos para el modelo.
Lo que ofrezco:
1. Limpieza profesional de datos
2. Análisis exploratorio profundo de datos (EDA)
3. Ingeniería avanzada de características
Herramientas y tecnologías:
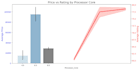
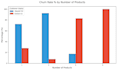
Utilizo Python con bibliotecas estándar de la industria: Pandas, NumPy, Seaborn, Matplotlib y Scikit-learn.
Entregables: Recibirás un conjunto de datos limpio (CSV/Excel) y un cuaderno de Jupyter completamente documentado (.ipynb) con todo el código y visualizaciones.


Traducción automática
¿Qué debo proporcionar para comenzar?
Por favor, proporciona tu conjunto de datos en formato CSV, Excel o SQL junto con una breve descripción de tus objetivos. Si tienes preguntas específicas que quieres que responda el Análisis Exploratorio de Datos (EDA), ¡no dudes en listarlas!
¿Qué herramientas usas para limpieza de datos y EDA?
Principalmente uso Python con potentes bibliotecas como Pandas y NumPy para manipulación de datos, y Matplotlib o Seaborn para visualizaciones de datos de alta calidad.
¿Puedes manejar conjuntos de datos muy desordenados con valores faltantes?
¡Sí! Esa es mi especialidad. Utilizo técnicas avanzadas de imputación (media, mediana, modo o llenado predictivo) y detección de valores atípicos para asegurar que tus datos sean consistentes y estén listos para el análisis.
¿Qué es "Feature Engineering" y por qué lo necesito?
El "Feature Engineering" es el proceso de crear nuevas variables a partir de tus datos en bruto para ayudar a que los modelos de Machine Learning funcionen mejor. Por ejemplo, convertir una columna "Fecha" en "Día de la semana" o "Es feriado". Añade un valor significativo a tus modelos predictivos.
¿A qué se refiere "100 items cleaned" en tus paquetes?
En la categoría de limpieza de datos, Fiverr establece un mínimo de 100 items. Considero estos "items" como puntos de datos o filas. Mi paquete básico está diseñado para ofrecer limpieza y EDA de alta calidad para conjuntos de datos estándar. Si tu archivo tiene varios miles de filas, no te preocupes, puedo manejarlo dentro del paquete listado.
¿Obtendré el código fuente?
Por supuesto. Entregaré un Jupyter Notebook (.ipynb) bien documentado o un script en Python para que puedas ver exactamente cómo se transformaron y recrearon los datos en el futuro.
¿Mis datos están seguros con ustedes?
Sí, tomo muy en serio la privacidad de los datos. Tus datos solo se usarán para el alcance del proyecto y serán eliminados de mi sistema una vez que el pedido esté completado y aceptado.


