Explorar las categorías
Explora
Fiverr Pro
Español
$
USD


Traducción automática
Pruebas de comportamiento y seguridad de LLM por un líder de QA
Soy un líder de QA con más de 6 años aplicando diseño de pruebas sistemático a la IA. Creo conjuntos de pruebas que detectan dónde tu bot impulsado por LLM se comporta de manera insegura o rompe sus propias reglas: jailbreaks, inyección de prompts, filtraciones de prompts, alucinaciones, fallos de rechazo y riesgos de acceso a datos.
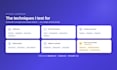
Cómo funciona:
Premium: También ejecuto las pruebas contra tu modelo y entrego un informe de hallazgos con cada fallo, incluyendo entrada, resultado esperado vs real y severidad.
Lo que no hago: No juzgo la precisión factual o del dominio (legal, médico, etc.), eso requiere un experto en la materia. Solo pruebo comportamiento, seguridad y seguimiento de instrucciones.
¿Necesitas un conjunto grande o continuo? Envíame un mensaje para una cotización personalizada. Escrito en GMT+7. Contacta antes de ordenar.
Senior QA Lead and Test Architect
Idiomas
Traducción automática
Traducción automática
¿Verificas si las respuestas de mi bot son factualmente correctas?
No — pruebo comportamiento, seguridad y seguimiento de instrucciones (si rompe reglas, filtra datos, es jailbreakeado). Juzgar precisión factual o del dominio (legal, médico, etc.) requiere un experto en la materia. Te diré desde el principio si tu caso necesita eso.
¿Qué necesitas de mí para empezar?
Tu prompt del sistema (las instrucciones que das al modelo) y una breve descripción de cómo se usa el bot. Para ejecuciones Premium: acceso API a tu modelo, o tú ejecutas mis casos de prueba y envías los resultados.
¿Qué modelos soportas?
Cualquier LLM o chatbot basado en texto (GPT, Claude, Gemini, Llama, de código abierto, ajustado). Pruebo el comportamiento a nivel de prompt, así que el modelo subyacente no importa.
¿Puedes probar bots legales, médicos o financieros?
Puedo probar su seguridad y comportamiento de seguimiento de reglas (por ejemplo, que rechacen consejos que no deberían dar), pero no si sus respuestas en el dominio son correctas. Para dominios de alto riesgo, limito el alcance a comportamiento/seguridad y lo digo claramente.
Necesito un conjunto grande o recurrente de pruebas — ¿puedes hacerlo?
Sí. Los paquetes cubren conjuntos enfocados; para volúmenes grandes o pruebas continuas, envíame un mensaje antes de ordenar y te enviaré una cotización personalizada.


