Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniero de datos, pipelines ETL, experto en Spark y data warehouse en la nube
¿Tienes problemas con transferencias manuales de datos, scripts rotos o tuberías de datos poco confiables? Te construiré una tubería ETL lista para producción que extrae, transforma y carga tus datos automáticamente, ahorrándote horas de trabajo manual cada semana.
Lo que entrego:
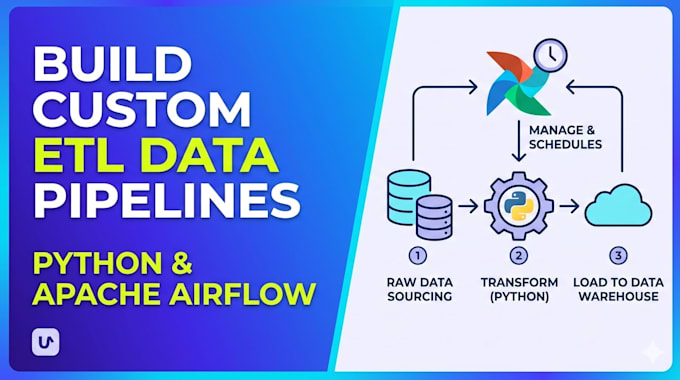
- Tubería ETL personalizada creada en Python con código limpio y documentado
- DAG de Apache Airflow para programación y monitoreo automatizados
- Soporte para todas las principales fuentes de datos: bases de datos (PostgreSQL, MySQL), APIs, CSV/Excel, S3, Google Sheets
- Lógica de transformación y limpieza de datos adaptada a tus reglas de negocio
- Manejo de errores, lógica de reintentos y alertas por email/Slack en caso de fallos
- Despliegue en tu infraestructura en la nube (AWS, GCP, Azure) o en servidor local
- Documentación completa para que tu equipo pueda mantenerla de forma independiente
Tecnologías que uso: Python, Apache Airflow, Apache Spark, Pandas, SQLAlchemy, AWS Glue, AWS Lambda, S3, PostgreSQL, MySQL, BigQuery, Snowflake.
Para quién es esto:
- Startups que están creando su primera tubería de datos automatizada
- Empresas que migran de flujos de trabajo manual en Excel/CSV a ETL automatizado
- Equipos que reemplazan una tubería de datos legacy rota o lenta
- Compañías que necesitan una tubería de ingesta de datos para Snowflake o BigQuery

Traducción automática
¿Qué fuentes de datos puedes conectar?
¿Qué fuentes de datos puedes conectar? Puedo conectar a cualquier base de datos SQL (PostgreSQL, MySQL, MSSQL), APIs REST, archivos CSV/JSON/Excel, almacenamiento en la nube (S3, GCS), Google Sheets y herramientas SaaS como Salesforce o HubSpot mediante conectores.
¿Necesito una cuenta en la nube?
Para despliegues en la nube necesitaré acceso a tu cuenta de AWS/GCP/Azure. Para despliegues locales solo necesito acceso SSH al servidor. También puedo ofrecer una solución basada en Docker que puedas ejecutar en cualquier lugar.
¿Podré mantener la tubería yo mismo?
Sí. Cada tubería que entrego viene con documentación completa, comentarios en el código y un video explicativo para que tu equipo pueda mantenerla y extenderla sin mi ayuda.
¿Qué pasa si necesito cambios después del parto?
Los paquetes estándar y premium incluyen revisiones. También ofrezco un paquete de mantenimiento pagado si deseas soporte continuo.
¿Cuánto tiempo tarda una tubería ETL típica?
¿Cuánto tiempo tarda una tubería ETL típica? Una tubería sencilla de una sola fuente tarda entre 2 y 3 días. Una tubería con múltiples fuentes y programación en Airflow tarda entre 4 y 6 días. Siempre confirmo el plazo antes de que hagas tu pedido.
