Explorar las categorías
Explora
Fiverr Pro
Español
$
USD



Traducción automática
¿Eres investigador, estudiante de doctorado o profesional de biotecnología que busca identificar posibles candidatos a fármacos mediante métodos computacionales?
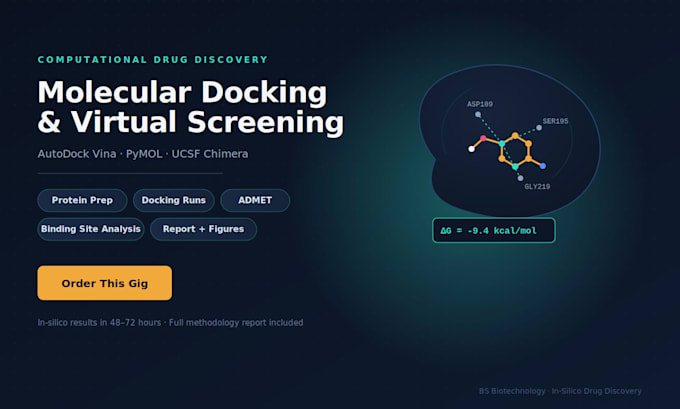
Soy investigador en biología computacional con experiencia práctica en descubrimiento de fármacos basado en estructuras. Mi investigación del último año incluyó el descubrimiento in silico de inhibidores para la toxina CARDS de Mycoplasma pneumoniae, identificando 2 compuestos principales a partir de grandes bibliotecas usando AutoDock Vina, validados mediante filtros ADMET y de farmacocinética Lipinski/Veber.
Lo que ofrezco:
Preparación de proteínas objetivo desde PDB
Docking molecular usando AutoDock Vina
Cribado virtual de bibliotecas de compuestos
Evaluación de ADMET y similitud a fármacos (Lipinski, Veber)
Análisis de interacción ligando-proteína (PyMOL)
Informe claro, listo para publicación, con visualizaciones
Herramientas: AutoDock Vina, PyMOL, UCSF Chimera, RCSB PDB, ChEMBL, SwissADME
Envíame un mensaje antes de hacer tu pedido para discutir tu proteína objetivo y el alcance del proyecto.
molecular docking, Ai Driven Drug Discovery,3D models
Idiomas
Traducción automática