Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Lo que puedo hacer:
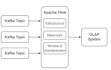
Conectividad completa a fuentes de datos (multi-fuente / pipelines complejos)
Integración de API + integración con sistemas externos
Funciones avanzadas de Flink (checkpointing, gestión de estado, windowing, joins)
Optimización del sistema y ajuste de rendimiento
Guía para el diseño de arquitectura
Formateo y limpieza
Incluye código fuente completo + documentación
"Ingeniero de datos absolutamente brillante. Configuró a la perfección nuestro pipeline de streaming de Kafka a Flink para nuestro MVP. El código era limpio, bien documentado y entregado justo a tiempo."
-- David L., Líder técnico
"Teníamos problemas con la gestión de estado y windowing en nuestro proceso ETL en tiempo real. No solo corrigió nuestros errores, sino que también optimizó toda la arquitectura de Flink. ¡Muy recomendable para flujos de datos complejos!"
-- Alex R., Arquitecto de datos
"Rápido, profesional y con profunda experiencia en Apache Flink. Integró sin problemas múltiples APIs externas en nuestro flujo de datos y ajustó el rendimiento perfectamente para producción. Volveré a contratarlo."
-- Sarah M., Fundadora de startup



Experiencia:
Big data
•
Flujo de Datos
•
etl
Tecnología:
Apache Kafka
•
apache spark
•
Java
•
Python
•
Scala
•
Otros


