Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
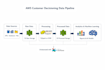
Soy un Ingeniero de Datos Senior con más de 6 años de experiencia diseñando pipelines de datos escalables y plataformas de datos en la nube. Me especializo en construir flujos de trabajo ETL confiables, transformar datos en bruto en conjuntos de datos estructurados y habilitar sistemas de datos listos para análisis.
Puedo ayudarte con:
-Desarrollo de pipelines ETL usando Python, SQL y PySpark
-Ingesta de datos desde APIs, archivos y bases de datos
-Transformación y optimización de datos
-Pipelines de datos en la nube usando AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
-Arquitectura Lakehouse (capas Bronze, Silver, Gold)
-Integración y ajuste de rendimiento en data warehouse
Me enfoco en construir pipelines de datos eficientes, escalables y listos para producción que soporten análisis, informes y flujos de trabajo de machine learning.
Si necesitas ayuda para diseñar o mejorar tu pipeline de datos o plataforma de datos, no dudes en contactarme antes de hacer un pedido.

Plataforma de almacenes:
Snowflake
•
redshift
•
PostgreSQL/Greenplum
Tipo de proyecto:
Nueva creación
