Explorar las categorías
Explora
Fiverr Pro
Español
$
USD

Level 2


Traducción automática
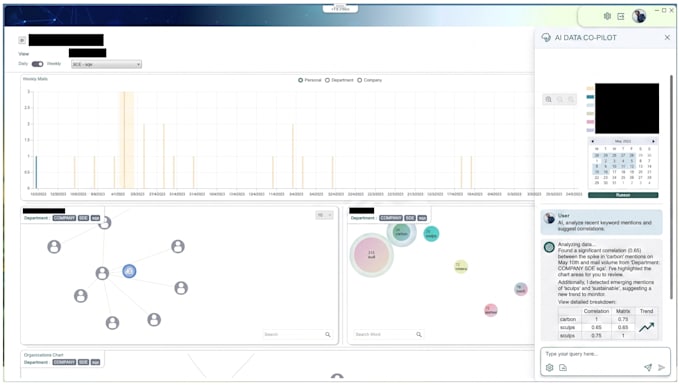
Tus clientes no te permitirán enviar sus datos a ChatGPT. Lo entiendo. Te construiré una aplicación de escritorio para Windows que ejecute un verdadero LLM Phi-3, Llama 3, Mistral, Qwen o Gemma completamente en la máquina del usuario
No en la nube. No claves API. No filtraciones de datos. No facturas recurrentes de OpenAI. Sin dolores de cabeza por GDPR. Sin preocupaciones por HIPAA.
Soy un desarrollador de Windows senior (más de 13 años) que actualmente trabaja en herramientas de depuración de hardware en una empresa global de silicio. Entiendo ONNX Runtime, DirectML, aceleración GPU/NPU y cómo distribuir un modelo de 24 GB dentro de un instalador MSIX o Inno Setup sin romperlo.
Perfecto para:
Pila tecnológica: C# / WPF/ WinUI, ONNX Runtime GenAI, llama.cpp, Microsoft.ML.OnnxRuntime, DirectML, Semantic Kernel (modo local), LiteDB para almacenamiento vectorial, empaquetado MSIX / Inno Setup
Requisitos de hardware que te ayudaré a planear: recomendaré especificaciones mínimas para tus usuarios finales según el tamaño del modelo
Windows Desktop Developer C Sharp, C plus plus , Python , WPF, XAML, AI
Level 2
Idiomas
Traducción automática
Traducción automática
¿Qué tan buenos son los modelos locales en comparación con GPT-4?
Honestamente, no son tan buenos en todo, pero sorprendentemente cercanos en muchas tareas. Phi-3-mini y Llama 3 8B manejan muy bien preguntas y respuestas, resumen, extracción y redacción. Para tareas que requieren conocimiento amplio del mundo o razonamiento complejo, los modelos en la nube aún lideran.
¿Qué tamaño tiene el instalador final?
Entre 2 GB y 8 GB, dependiendo del modelo. Uso instaladores que descargan el modelo en la primera apertura si prefieres una descarga inicial más pequeña.
¿Funcionará esto en una laptop de 5 años?
Sí, con un modelo más pequeño (Phi-3-mini, 3.8B parámetros) en CPU — más lento, quizás 3 a 6 tokens por segundo. Para respuestas en tiempo real, se recomienda 16 GB de RAM y un CPU moderno.
¿Puede usar el NPU en PCs más recientes con Copilot+?
Sí. ONNX Runtime con DirectML puede dirigirse al NPU en Qualcomm Snapdragon X y en NPUs más nuevos de Intel / AMD para inferencias mucho más rápidas y menor consumo de energía.
¿Qué pasa si quiero actualizar el modelo después?
Los paquetes Estándar y Premium incluyen un mecanismo de intercambio de modelos para que tú (o tus usuarios) puedan reemplazar un modelo por uno más nuevo o diferente sin necesidad de un nuevo instalador.
¿Realizas ajuste fino?
El ajuste fino es un servicio aparte. Para la mayoría de los casos, RAG (recuperar de tus propios documentos) te da el mismo resultado práctico sin el costo y la complejidad del ajuste fino. Te aconsejaré honestamente sobre cuál necesitas.
¿Puedes firmar un HIPAA BAA?
No firmo BAAs como freelancer individual, pero tu app puede ser compatible con HIPAA por diseño — que es exactamente lo que construyo. Explicaré la diferencia en nuestra primera charla.
¿Qué hay sobre la licencia comercial de los modelos?
Solo uso modelos con licencias permisivas (Phi-3 MIT, Llama 3 con licencia comercial de Meta, Mistral Apache 2.0, Qwen). Avisaré sobre implicaciones de licencias antes de que finalicemos qué modelo usar.