Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ciencia de datos e inteligencia artificial
¿Buscas algo más que un script básico de NLP?
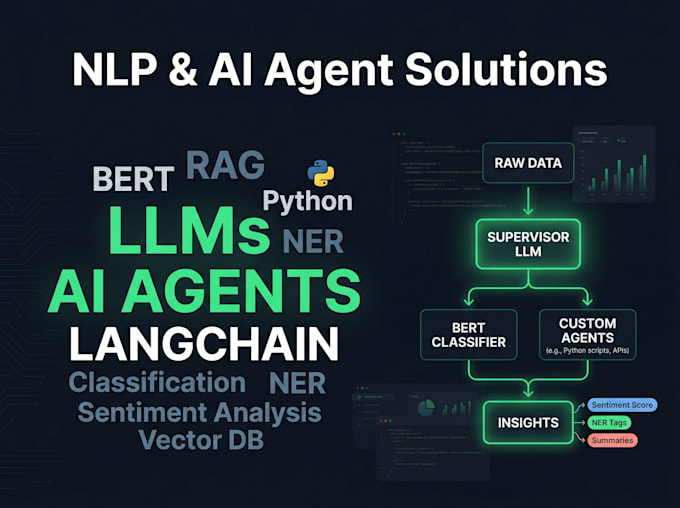
Construyo sistemas inteligentes de texto de extremo a extremo, desde pipelines clásicos de NLP hasta modelos fine-tuned de BERT y agentes de IA listos para producción, impulsados por LangGraph y LangChain. Ya sea que necesites un clasificador de sentimientos, un chatbot específico para un dominio o un sistema completo de múltiples agentes LLM, entrego soluciones limpias, documentadas y desplegables.
Lo que ofrezco:
1. NLP y análisis de texto
Preprocesamiento de texto: tokenización, eliminación de stopwords, lematización (spaCy / NLTK)
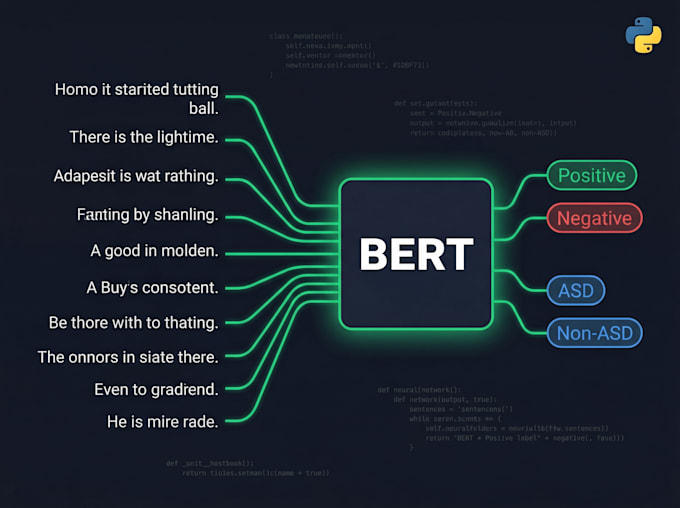
Clasificación de texto y análisis de sentimientos (Naive Bayes, SVM, Regresión logística)
Reconocimiento de entidades nombradas (NER), extracción de palabras clave y frases clave
TF-IDF, análisis de n-gramas, frecuencia de palabras, redes de co-ocurrencia
Modelado de temas: LDA, NMF, BERTopic
Resumen de texto y similitud semántica
2. Fine-tuning de BERT y Transformer
Ajuste fino de BERT, RoBERTa, DistilBERT, AraBERT en tu conjunto de datos personalizado
Clasificación de secuencias, clasificación de tokens, respuesta a preguntas
Curvas de entrenamiento, informe de evaluación (precisión, F1, matriz de confusión)
Guardar y exportar pesos del modelo (formato HuggingFace, .pth, .zip)
3. Agentes de IA y soluciones LLM
Orquestación multi-agente usando LangGraph, dominio específico



Lenguaje de programación:
Python
•
MATLAB
•
SQL
•
Colab
Marcos:
Scikit-learn
•
PyTorch
•
Panda
API:
Otros
Herramientas:
Jupyter Notebook
•
opencv
•
TensorFlow
•
Excel
•
Colab
Traducción automática
Q1: ¿Con qué tipo de datos de texto puedes trabajar?
Cualquier dominio — texto médico/clínico, reseñas de clientes, publicaciones en redes sociales, comentarios de YouTube, documentos legales, artículos académicos, informes financieros, respuestas a encuestas. Si tienes texto, puedo construir algo con ello.
Q2: ¿Necesito un conjunto de datos etiquetado para clasificación?
Para tareas supervisadas (clasificación, sentimientos) — sí, se necesita datos etiquetados. Para tareas no supervisadas (modelado de temas, clustering, extracción de palabras clave) — texto en bruto está bien. También puedo asesorar sobre la estrategia de etiquetado si estás empezando desde cero.
Q3: ¿Puedes construir un sistema RAG para mis documentos o base de conocimientos?
Sí — esto entra en el paquete Premium. Configuraré un almacén de vectores (FAISS o Chroma), lo conectaré a tus documentos y construiré un pipeline de recuperación con LangChain para que tu LLM responda preguntas estrictamente con tus datos.
Q4: ¿Con qué LLMs trabajas?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Puedo trabajar con cualquiera que prefieras o a quien ya tengas acceso vía API. También puedo usar modelos open-source locales mediante Ollama si quieres evitar costos de API.
Q5: ¿Podré ejecutar y modificar el código yo mismo?
Por supuesto. Todos los entregables son notebooks Jupyter/Colab limpios y bien comentados. Escribo código para humanos, no solo para máquinas. Entenderás cada paso y puedo explicarlo después de la entrega.
Q6: ¿Puedes desplegar el modelo o agente como una API o aplicación web?
El despliegue básico (endpoint FastAPI o app Streamlit) puede añadirse como extra. Para despliegue completo en la nube (AWS, GCP, Hugging Face Spaces), contáctame antes de ordenar para una cotización personalizada.