Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Lo que hacemos
Servicios clave
Proceso
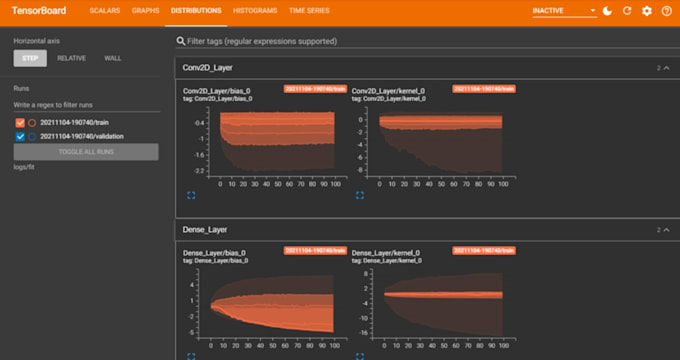
Pila tecnológica
PyTorch, TensorFlow, HF, scikit-learn, Optuna, MLflow, ONNX/TensorRT, Docker/FastAPI
Propiedad
Tú eres dueño del código y los pesos. Los costos de GPU en la nube se facturan según las tarifas del proveedor. NDA/etiqueta blanca disponible.
Para comenzar

Lenguaje de programación:
Python
•
MATLAB
•
Colab
•
MLflow
•
Julia
Marcos:
Scikit-learn
•
DeepPy
•
keras
•
PyTorch
•
Panda
•
TensorFlow
Traducción automática
¿Firmará un NDA?
Sí. Me siento cómodo con NDA y/o una cláusula de confidencialidad mutua. También está bien trabajar con marca blanca.
¿Cómo protegen mis datos?
Acceso con privilegios mínimos, repositorios privados, almacenamiento encriptado (cuando se usa la nube) y sin compartir con terceros. Elimino conjuntos de datos y artefactos a petición o 14 días después de la entrega.
¿Quién es el dueño del modelo y del código?
Tú. Transferencia completa de pesos entrenados, código fuente y documentación. Nota: los modelos base/bibliotecas de código abierto mantienen sus licencias originales.
¿Cuáles son los plazos de entrega típicos?
Básico: 7 días, Estándar: 14 días, Premium: 28 días. Opciones extra rápidas están disponibles en Extras.
¿Qué puede afectar los plazos?
Tamaño/calidad de los datos, etiquetado, número de pruebas HPO, requisitos de cumplimiento y complejidad del despliegue (nube, escalado, seguridad).
¿Puedes desplegar el modelo para uso en producción?
Sí. La opción Premium incluye despliegue en la nube; la Estándar entrega una estructura de API. Puedo proporcionar una API REST Dockerizada con verificaciones de salud y documentación.
¿Qué stacks soportas?
PyTorch/TensorFlow, Hugging Face, ONNX/TensorRT, FastAPI + Docker. Me integro con AWS/GCP/Azure, Vercel/DO o tu infraestructura local.
¿Obtengo exportaciones para móvil/edge?
Sí, exportación del modelo a ONNX; TFLite/Core ML a petición, sujeto a compatibilidad del modelo.
¿Qué incluye la documentación?
Notas de configuración, comandos de ejecución, especificaciones del endpoint, informe de evaluación y una tarjeta del modelo que cubre métricas, datos y limitaciones.
¿Da mantenimiento?
Sí. Se ofrece mantenimiento mensual opcional (corrección de errores, pequeñas actualizaciones) como Extra o en un plan personalizado.