Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
FREELANCER HABILIDOSO COMPROMETIDO CON CONTENIDOS DE CALIDAD
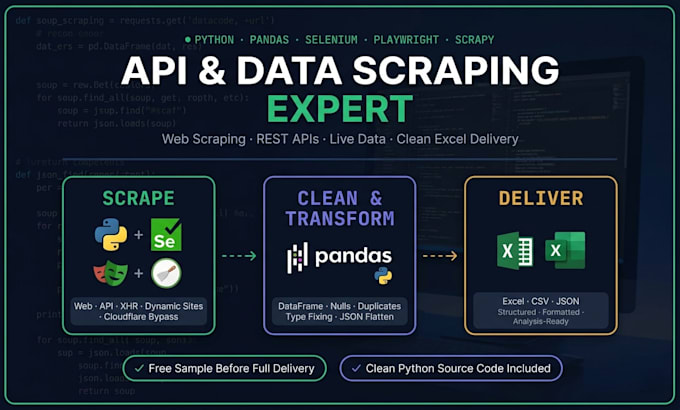
Extraeré datos de sitios web dinámicos y endpoints de API.
¿Necesitas datos de cualquier sitio web, API oculta o fuente en vivo estructurada, limpia y lista para usar? Estás en el lugar correcto.
Me encargo tanto de web scraping dinámico como de extracción de endpoints de API desde páginas renderizadas con JavaScript hasta APIs XHR/Fetch invertidas, y entrego todo a través de un completo pipeline de limpieza y formateo con Pandas.
LO QUE RECIBES:
Scraping de sitios web dinámicos
Descubrimiento y ingeniería inversa de endpoints de API (XHR/Fetch)
Scraping de tokens, encabezados de autenticación y manejo de sesiones en REST API
Saltarse Cloudflare, Turnstile y protección anti-bots
Datos en tiempo real: resultados deportivos, criptomonedas, precios, listados
JSON anidado convertido en hojas estructuradas
Salida en Excel / CSV / JSON
️ TECNOLOGÍAS:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
¿POR QUÉ ELEGIRME?
Cobertura completa en web scraping y extracción de API en un solo vendedor
Muestra gratis antes de la entrega completa
Script de Python reutilizable incluido con cada pedido
Solo archivos limpios, tipados y formateados, sin dumps en crudo
Especialista en Turnstile y Cloudflare
Envíame un mensaje primero para verificar la viabilidad, sin compromiso.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Tecnología:
Python
•
Excel
•
Selenium
•
Beautiful Soup
•
Pandas
Tipo de información:
Sitios web
Técnica:
Automatizado
Traducción automática
Q1: ¿Cuál es la diferencia entre web scraping y extracción de API?
Web scraping extrae datos directamente del HTML de un sitio web, útil para páginas sin API pública. La extracción de API intercepta las llamadas backend ocultas que realiza un sitio (solicitudes XHR/Fetch) para obtener datos más limpios, rápidos y confiables. Hago ambas cosas, según lo que mejor funcione para tu sitio específico.
Q2: ¿Puedes extraer sitios web renderizados con JavaScript o dinámicos?
Sí. Uso Selenium y Playwright para renderizar completamente páginas con JavaScript, manejar desplazamiento infinito, carga perezosa y contenido AJAX antes de extraer datos, para que no se quede nada fuera.
Q3: ¿Puedes saltarte la protección de Cloudflare o Turnstile?
Sí. Tengo experiencia práctica capturando tokens de Cloudflare Turnstile, incluyendo desafíos activados por desplazamiento y basados en user-agent, uno de los sistemas de protección contra bots más complejos en uso actualmente. Envíame un mensaje con tu sitio objetivo para una revisión de factibilidad gratuita.
Q4: ¿Qué significa realmente "limpieza y formateo de datos"?
Antes de entregar, cada conjunto de datos pasa por un pipeline completo de Pandas: manejo de valores nulos, eliminación de duplicados, corrección de tipos de datos, estandarización de nombres de columnas, aplanamiento de JSON anidado y formateo en Excel con encabezados y anchos adecuados. Recibes un archivo terminado y profesional, no un dump en crudo.
Q5: ¿Recibiré el script en Python?
Sí, cada pedido incluye código fuente en Python limpio, comentado y reutilizable, para que puedas volver a ejecutar el scraper en cualquier momento sin contratar de nuevo.
Q6: ¿Qué formatos de salida entregas?
Por defecto, Excel (.xlsx), CSV y JSON. Entrega en Google Sheets disponible bajo petición. Solo menciona tu preferencia antes de ordenar.
Q7: ¿Es legal hacer web scraping?
Solo trabajo con datos de acceso público y no scrapeo sitios que prohíben explícitamente en sus Términos de Servicio. Nunca extraigo datos privados de usuarios ni evado muros de pago. Envíame un mensaje con tu URL objetivo antes de ordenar para confirmar la factibilidad y el cumplimiento.
Q8: ¿Cómo empiezo?
Envíame un mensaje antes de hacer un pedido. Comparte tu URL objetivo, los campos de datos que necesitas y el volumen aproximado. Confirmaré la factibilidad, el plazo y cualquier desafío técnico, completamente gratis y sin compromiso.