Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Proyectos de sistemas y ML en C Python SQL a tiempo y optimizados
¿Estás ahogado en PDFs, facturas, formularios o imágenes escaneadas que necesitan extraer datos? Construyo sistemas de AI listos para producción que lo hacen automáticamente.
Soy ingeniero en AI y visión por computadora con experiencia práctica en construir pipelines de deep learning de principio a fin, desde datos en bruto hasta una solución funcional y desplegable que realmente puedas usar.
LO QUE CONSTRUYO
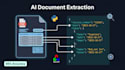
Procesamiento inteligente de documentos (IDP)
Extrae datos estructurados de facturas, recibos, contratos, formularios médicos, documentos fiscales y cualquier formato PDF o imagen personalizado.
Pipeline de OCR personalizado
Más allá del OCR básico, construyo sistemas de AI que entienden el diseño, tablas, casillas y escritura a mano usando TesseractOCR, PaddleOCR y deep learning.
Visión por computadora y detección de objetos
Modelos YOLO (v8/v11) personalizados, clasificación de imágenes, segmentación y seguimiento de objetos entrenados con tu propio conjunto de datos.
Desarrollo de modelos AI/ML
CNN, RNN, LSTM para clasificación, regresión, extracción de texto NLP y pronósticos de series temporales.
Despliegue de modelos y API
API REST mediante FastAPI o Flask, contenedorización con Docker, despliegue en la nube (AWS, GCP), integración con tu frontend.
HERRAMIENTAS Y STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Traducción automática
¿Necesito proporcionar datos de entrenamiento?
Depende del proyecto. Para tipos comunes de documentos como facturas o recibos, puedo usar modelos preentrenados y adaptarlos a tu formato. Para documentos muy personalizados o diseños propietarios, un conjunto de datos de muestra de 50 a 200 ejemplos es ideal. Si no tienes uno, puedo guiarte sobre cómo recopilar y
¿En qué formato se entregarán los datos extraídos?
Por defecto entrego salida estructurada en JSON o CSV. Si necesitas que esté en una base de datos, archivo Excel o integrado en tu sistema mediante API, eso se puede organizar — solo menciónalo cuando me contactes.
¿Qué precisión tendrá la extracción?
La precisión depende de la calidad y complejidad del documento. Para PDFs digitales y limpios, generalmente alcanza entre 95 y 99%. Para documentos escaneados o escritos a mano, entre 85 y 95% es realista. Siempre pruebo con tus documentos reales antes de entregar y incluyo un informe de rendimiento.
¿Puedes trabajar con documentos en otros idiomas además del inglés?
Sí. PaddleOCR soporta más de 80 idiomas y tengo experiencia con pipelines multilingües. Por favor, menciona tu idioma cuando me contactes.
¿Seré dueño del código?
Sí, al 100%. Todo el código fuente, pesos del modelo y documentación son tuyos. No retengo ningún derecho sobre lo que construyo para ti.


