Explorar las categorías
Explora
Fiverr Pro
Español
$
USD





Traducción automática
¿Cansado de procesar documentos manualmente? Deja que la IA lo haga en segundos.
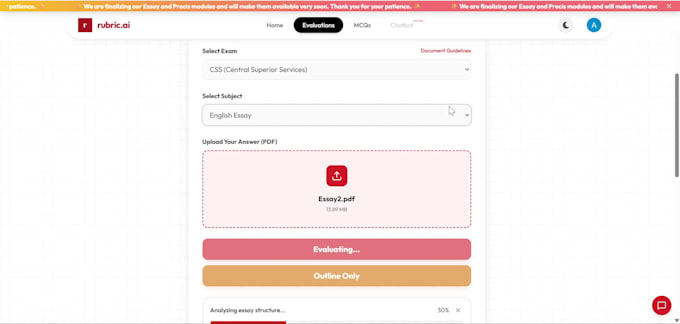
Construiré una pipeline personalizada de OCR e inteligencia de documentos que extrae, procesa y analiza texto de PDFs, archivos escaneados, hojas manuscritas e imágenes, entregando un resultado limpio, estructurado y listo para producción.
He construido y desplegado sistemas reales de OCR como Rubric Ai incluyendo una plataforma de evaluación de exámenes con IA y sistemas automatizados de procesamiento de facturas con usuarios reales, no solo proyectos secundarios.
Lo que construyo: pipeline de OCR para PDFs, imágenes y documentos escaneados, preprocesamiento para entradas ruidosas, manuscritas y de baja calidad, análisis con LLM y extracción inteligente de texto, anotaciones automáticas y motor de evaluación, salida estructurada en JSON/CSV lista para integración, backend con FastAPI e integración con bases de datos
Perfecto para: procesamiento de documentos legales, médicos y financieros, automatización de exámenes, evaluaciones y calificaciones, extracción de datos de facturas, recibos y contratos
Por qué elegirme: sistemas de OCR desplegados reales, no solo tutoriales, manejo de escritura a mano, idiomas mezclados y escaneos de mala calidad, código limpio, fuente completa incluida, entrega puntual
Envíame un mensaje y definamos el alcance de tu proyecto antes de que hagas tu pedido.
Ai and Computer vision Solutions
Idiomas
Traducción automática
Traducción automática
¿Puedes construir un sistema personalizado de evaluación o calificación de documentos?
Por supuesto. He creado motores de evaluación con LLM basados en rúbricas que califican y anotan documentos sección por sección. Ya sea para calificación de exámenes, revisión de contratos o validación de formularios, puedo construir una pipeline de evaluación inteligente adaptada a tus criterios.
¿Qué tipos de documentos puede procesar tu pipeline de OCR?
Mi pipeline de OCR maneja PDFs, imágenes escaneadas, documentos fotografiados y hojas manuscritas. Funciona con escaneos de baja calidad, contenido en idiomas mezclados y entradas ruidosas, incluyendo preprocesamiento para garantizar una extracción de texto limpia y precisa en cada ocasión.
¿Puedes integrar el sistema de OCR con mi aplicación o base de datos existente?
Sí. Construyo backends REST con FastAPI que se conectan directamente a tu aplicación. Soporto MongoDB y PostgreSQL para almacenamiento estructurado y puedo entregar salida en JSON o CSV compatible con cualquier sistema downstream.
¿Qué es la inteligencia de documentos y en qué se diferencia del OCR básico?
El OCR básico solo extrae texto. La inteligencia de documentos va más allá — usando LLMs para analizar, clasificar, anotar y evaluar el contenido extraído según criterios definidos. Es la diferencia entre leer un documento y entenderlo realmente.
¿Proporcionáis código fuente y documentación?
Sí, cada entrega incluye el código fuente completo, comentarios detallados y documentación de configuración para que tu equipo pueda mantener y ampliar el sistema de forma independiente sin depender de mí.
¿Cuánto tiempo tarda en construirse una pipeline completa de inteligencia de documentos?
Una pipeline básica de extracción OCR tarda 3 días. Un sistema completo de inteligencia de documentos con análisis con LLM, motor de anotaciones, API e integración con base de datos suele tardar entre 7 y 10 días, dependiendo de la complejidad. Envíame un mensaje primero para obtener un cronograma preciso para tu proyecto.