Servicios profesionales de ingeniería de datos | Pipelines ETL | AWS | Databricks
¿Buscas construir pipelines de datos escalables y confiables para tu negocio?
Soy un ingeniero de datos con más de 6 años de experiencia diseñando y optimizando pipelines ETL usando tecnologías modernas de nube y big data.
Lo que puedo hacer por ti:
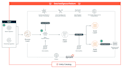
- Construir pipelines ETL de extremo a extremo (Extraer, Transformar, Cargar)
- Desarrollar trabajos PySpark / Spark para procesamiento de datos a gran escala
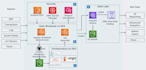
- Diseñar lagos de datos en AWS S3
- Crear flujos de trabajo usando Apache Airflow
- Implementar soluciones Databricks para análisis y ML
- Optimizar pipelines para rendimiento y eficiencia en costos
- Integrar datos desde APIs, bases de datos y archivos (CSV, JSON, Parquet)
️ Stack tecnológico:
- AWS: S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
¿Por qué elegirme?
- He construido pipelines que manejan conjuntos de datos de múltiples terabytes
- Foco fuerte en optimización de rendimiento
- Código limpio, mantenible y listo para producción
- Comunicación rápida y entrega confiable
Casos de uso de ejemplo:
- Pipelines para data warehouse
- Arquitectura de data lake
- Workflows por lotes y programados
- Limpieza y transformación de datos
- Pipelines de ingestión de API a S3