Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Haré ciencia de datos o análisis de datos.
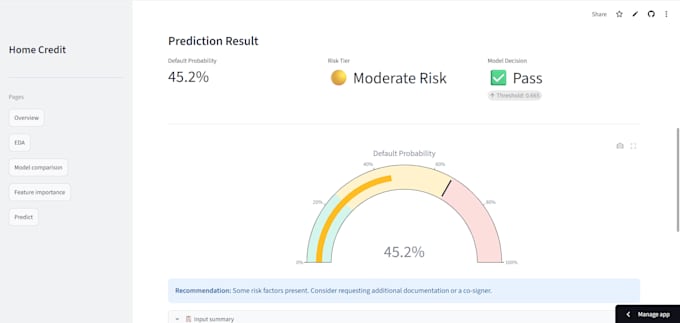
Demostración en vivo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
¿Tienes datos en bruto pero no sabes cómo convertirlos en un modelo de ML funcional? Crearé una pipeline completa de aprendizaje automático lista para producción, desde datos desordenados hasta un modelo que realmente funciona.
Lo que entregaré:
Limpieza de datos y ingeniería de características (manejo de valores faltantes, codificación, escalado)
Entrenamiento de modelos LightGBM, XGBoost, Random Forest o regresión logística
Optimización de hiperparámetros con Optuna para el mejor rendimiento
Informe completo de evaluación (AUC, F1-score, precisión, recall, matriz de confusión)
Pipeline de scikit-learn limpio, reproducible y listo para desplegar
Jupyter Notebook + código Python documentado
Repositorio en GitHub (a solicitud)
Por qué trabajar conmigo:
No solo entreno un modelo y se lo entrego. Documenté cada paso para que entiendas qué se hizo y por qué, y me aseguro de que la pipeline sea lo suficientemente limpia para reutilizarla o extenderla.
Revisa mi portafolio: credit-risk-prediction-better.streamlit.app
No dudes en enviarme un mensaje antes de ordenar, revisaré tu conjunto de datos y confirmaré si puedo ayudarte.



Lenguaje de programación:
Python
•
SQL
Marcos:
Scikit-learn
•
keras
•
PyTorch
Herramientas:
Jupyter Notebook
•
opencv
•
TensorFlow
•
Excel
•
Colab
Traducción automática
¿Con qué tipo de datos trabajas?
Trabajo con datos estructurados/tabulares — CSV, Excel o exportaciones SQL. Esto cubre problemas de clasificación (fraude, churn, riesgo crediticio) y problemas de regresión (predicción de precios, pronóstico de ventas). Para datos de imagen o texto, por favor envíame un mensaje primero para evaluar el alcance.
¿Qué pasa si mi conjunto de datos está desordenado o tiene valores faltantes?
Eso es completamente normal — manejar datos desordenados es parte de lo que hago. Los limpiaré, manejaré valores faltantes, codificaré características categóricas y escalaré las numéricas como parte de cada paquete.
¿Qué modelos de aprendizaje automático utilizas?
Principalmente LightGBM, XGBoost, Random Forest y Regresión Logística — dependiendo de tus datos y objetivo. En los paquetes Standard y Premium entreno y comparo múltiples modelos para que obtengas el mejor rendimiento.
¿Podré reutilizar o modificar el código yo mismo?
Sí. Todo el código está limpio, comentado y estructurado como una pipeline de scikit-learn adecuada — así es fácil volver a entrenar con nuevos datos o ajustar parámetros. También explicaré las partes clave para que no te quedes con dudas.