Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Construye aplicaciones web inteligentes con IA y soluciones de NLP para datos
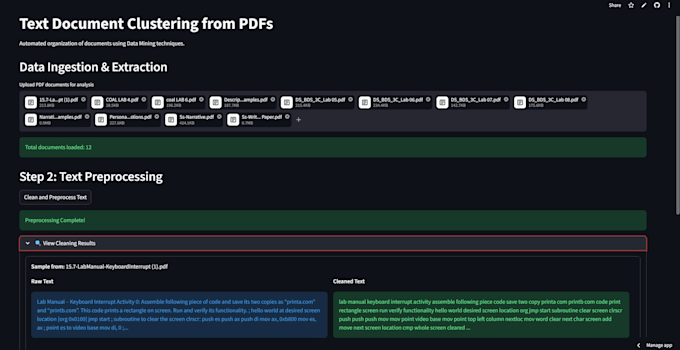
Título: Organización automatizada de documentos y análisis NLP
¡Hola! Si estás abrumado por una gran pila de documentos PDF, puedo ayudarte a organizarlos usando NLP impulsado por IA.
No solo agrupo archivos por palabras clave básicas. Utilizo embeddings semánticos avanzados para entender el significado real de tu texto, asegurando que tus documentos se clasifiquen de manera lógica y precisa.
Lo que ofrezco:
Me enfoco en la precisión y en un código limpio. ¡Envíame un mensaje hoy para discutir tu proyecto!




Lenguaje de programación:
Python
Marcos:
Scikit-learn
•
Panda
Herramientas:
Jupyter Notebook
•
Colab
Traducción automática
¿Qué tipo de documentos PDF puedes procesar?
Puedo procesar casi cualquier PDF basado en texto, incluyendo artículos de investigación, informes empresariales y artículos.
¿También puedes procesar archivos de Microsoft Word (.docx)?
¡Sí, por supuesto! Aunque la versión estándar de mi herramienta está optimizada para PDFs, puedo modificar fácilmente el pipeline de ingesta de datos para manejar archivos .docx y .doc.
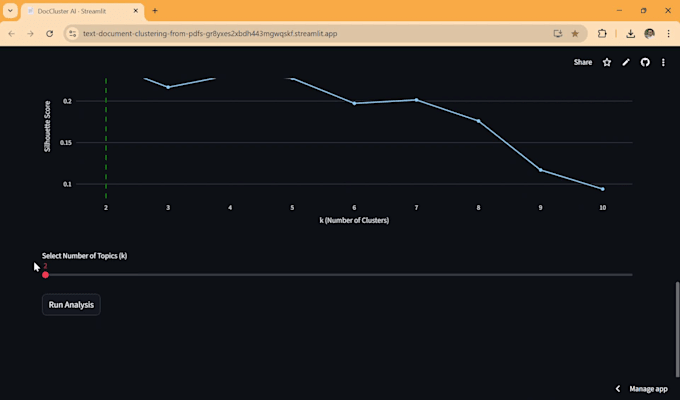
¿Cómo aseguras que los clusters sean precisos?
Utilizo un análisis de "Silhouette Score" para determinar matemáticamente el número más lógico de grupos para tus datos. Esto garantiza que los clusters no sean solo aleatorios, sino basados en una densidad semántica real.
¿Necesito proporcionar los "Temas" de antemano?
¡No! Esto es "Aprendizaje no supervisado", lo que significa que la IA identifica los patrones y agrupa los documentos por sí misma.
¿Mis datos están seguros?
Por supuesto. Procesaré tus datos localmente en mi entorno de desarrollo seguro. Una vez entregado y aceptado el proyecto, eliminaré tus documentos de mi sistema a menos que me indiques lo contrario.
¿Puedo ejecutar el dashboard de Streamlit en mi propia computadora?
Sí. Si eliges el paquete Premium, proporciono un archivo requirements.txt y una configuración .devcontainer, facilitando ejecutar la app localmente en VS Code o desplegarla en la nube.