Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Sobre mí,
Hola,
Soy Científico de Datos e Ingeniero de Aprendizaje Automático Junior con experiencia en la creación de modelos predictivos para diferentes ámbitos.
Crearé un modelo que predice resultados futuros usando técnicas de aprendizaje automático.
La elección del modelo (Random Forest, Regresión Logística, XGBoost, etc.) dependerá de tu conjunto de datos y del objetivo específico que quieras lograr, ya sea clasificación, regresión o pronóstico.
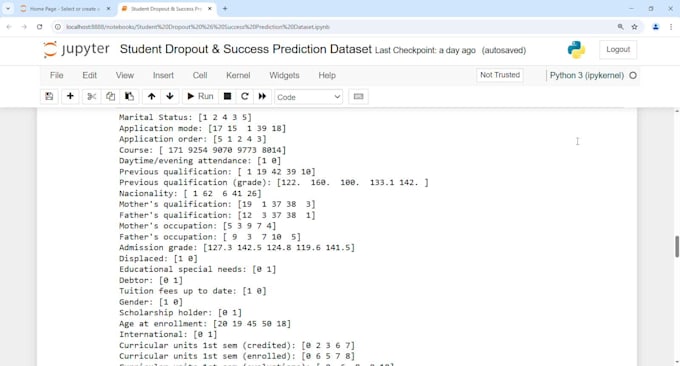
Uno de mis proyectos exitosos incluye predecir el estado del estudiante (abandono, inscripción, graduación) usando 36 características como registros académicos, datos demográficos y financieros con Random Forest.
Lo que obtendrás:
Si tienes un proyecto que involucra tareas de ciencia de datos o aprendizaje automático, estoy aquí para ayudarte.
He adquirido experiencia valiosa en proyectos a nivel industrial. También soy muy flexible y fácil de trabajar, y estoy comprometido a ofrecer valor y conocimientos claros.
Envíame un mensaje antes de hacer el pedido para que podamos encontrar la mejor solución para tus datos!



Lenguaje de programación:
Python
•
SQL
Marcos:
Scikit-learn
•
Panda
•
Otros
API:
Otros
Herramientas:
Jupyter Notebook
Traducción automática
¿Qué tipo de datos necesitas de mí para comenzar el proyecto?
Necesitaré tu conjunto de datos en un formato como CSV o Excel, junto con una breve explicación de qué significa cada columna y el resultado que quieres predecir (por ejemplo, estado del estudiante, rotación de clientes, etc.). Cuanto más contexto proporciones, mejor podré adaptar el modelo a tus necesidades.
¿Qué algoritmos de aprendizaje automático utilizas?
Elijo el algoritmo según tu conjunto de datos y objetivo. Algunos modelos comunes que uso son Random Forest, Regresión Logística, Árboles de Decisión, XGBoost y otros. Si tienes una preferencia o necesitas un modelo específico, solo dime!