Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
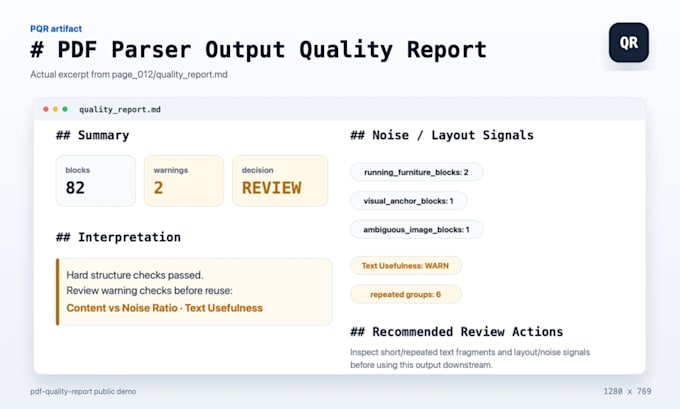
Your PDF extraction output looks usable, but you need it cleaned and checked before review, cleanup, schema mapping, or RAG ingestion preparation?
I review existing parser output from Docling, PyMuPDF, Unstructured, or similar tools and create:
The work starts from your goal: which fields matter, which IDs or source references must be preserved, and how you will use the output downstream.
What I need:
What I do not cover:

Tecnología:
Python
Which parser formats can you work with?
Docling JSON is the best fit. PyMuPDF, Unstructured, LlamaParse, or similar JSON/dict-style parser output may also work after a quick sample check.
Do you provide OCR or table reconstruction?
Not by default. This gig is for reviewing and cleaning existing parser output. Scanned documents, OCR cleanup, and complex table reconstruction need a custom scope after a sample check.
Is this a RAG system build?
No. I can prepare reviewable JSON, Markdown, or JSONL records for ingestion preparation, but I do not build the chatbot, retrieval system, vector database, or answer-quality evaluation.