Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
¿Tienes datos de expresión génica etiquetados y necesitas
un clasificador de machine learning para predecir subtipos de cáncer o resultados en pacientes?
Construiré una pipeline completa de clasificación ML
adaptada a tu conjunto de datos genómicos.
LO QUE OBTIENES:
- Preprocesamiento y normalización de datos
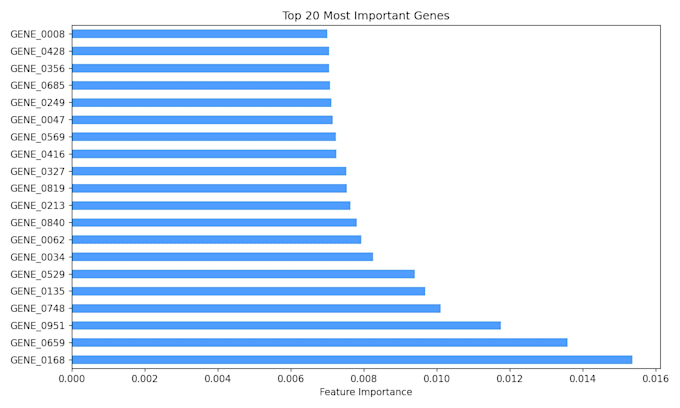
- Selección de características para identificar los genes más informativos
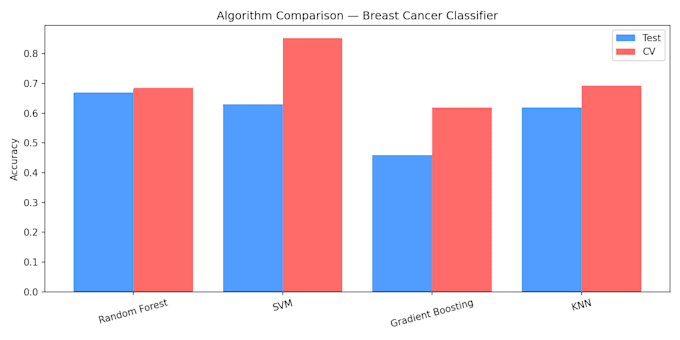
- Comparación de múltiples algoritmos (Random Forest, SVM,
Gradient Boosting, KNN)
- Evaluación de precisión mediante validación cruzada
- Matriz de confusión e informe de clasificación
- Visualización de la importancia de las características
- Modelo guardado listo para producción
MI EXPERIENCIA:
Construí un clasificador de subtipos de cáncer de mama usando datos de expresión génica logrando un 85.2% de precisión en validación cruzada con SVM. Clasifiqué 4 subtipos:
LuminalA, LuminalB, HER2, TripleNegativo.
Pipeline completo en GitHub.
LO QUE NECESITO DE TI:
- Matriz de expresión génica (muestras x genes)
- Etiquetas de subtipos o resultados para cada muestra
- Número de clases a predecir
- Genes o vías importantes conocidas
HERRAMIENTAS: Python, scikit-learn, Pandas, numpy,
matplotlib, seaborn, joblib, Linux, Git



Experiencia:
Clasificación
•
agrupación
•
Análisis predictivo
Lenguaje de programación:
Python
•
R
Marcos:
Scikit-learn
•
Panda
API:
Otros
Herramientas:
Jupyter Notebook
•
RStudio