Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniero de datos en la nube, BigQuery, Snowflake, dbt, Python, ETL
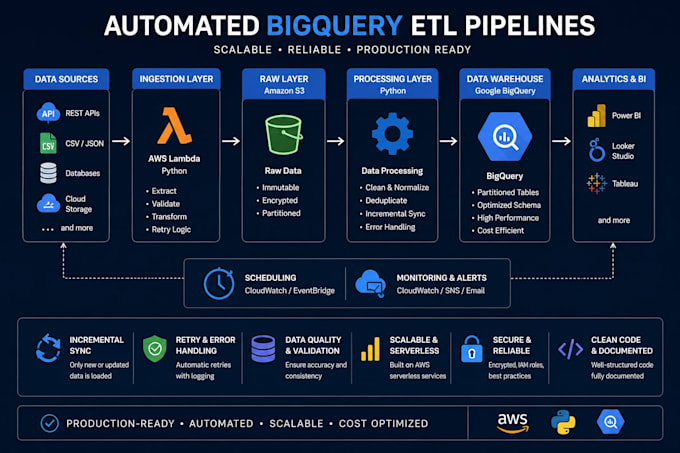
Construye un pipeline ETL escalable y listo para producción desde APIs, CSV, JSON, bases de datos o almacenamiento en la nube directamente en Google BigQuery.
Me especializo en pipelines de datos automatizados basados en Python para análisis, informes, Power BI, Looker Studio, Tableau y plataformas de inteligencia empresarial.
Los servicios incluyen:
Ingesta de API a BigQuery
Carga incremental de datos
Backfill histórico
Normalización de JSON / CSV
Pipelines programados automáticos
AWS Lambda / arquitectura sin servidor
Reintentos y manejo de errores
Registro y monitoreo
Deducción de datos duplicados
Tablas particionadas en BigQuery
Arquitectura de staging cruda y curada
Estructuras de almacén listas para dbt
Tecnologías:
- Python
- BigQuery
- AWS Lambda
- S3 / GCS
- Airflow / Prefect
- dbt
- APIs REST
Casos de uso típicos:
- Análisis de comercio electrónico
- Informes financieros
- Paneles de marketing
- Integraciones CRM
- Sistemas de informes automatizados
Me enfoco en arquitecturas escalables, mantenibles y listas para producción en lugar de scripts simples.
Por favor, contacta conmigo antes de hacer un pedido para proyectos personalizados o a gran escala.
Las revisiones no incluyen cambios importantes en el alcance ni integraciones adicionales.





Traducción automática
¿Soportas conjuntos de datos grandes?
Sí. Diseño pipelines escalables para millones de registros y cargas de trabajo en producción.
¿Puedes desplegar en AWS?
Sí. Puedo desplegar arquitecturas sin servidor usando Lambda, S3, Step Functions y CloudWatch.
¿Puedes optimizar los costos de BigQuery?
Sí. Uso particionado, clustering, procesamiento incremental y patrones de consulta optimizados.
¿Qué arquitectura prefieres para tu pipeline de datos?
Puedo construir el pipeline usando arquitectura nativa de AWS o GCP, dependiendo de tu infraestructura existente, presupuesto y requisitos de informes. 1. API → Cloud Run / Cloud Function → GCS Raw → BigQuery 2. API → Lambda → S3 Raw → BigQuery Data Transfer Service → BigQuery
¿Puedes construir pipelines ETL incrementales?
Sí. Prefiero fuertemente el procesamiento incremental sobre recargas completas para escalabilidad, menores costos en BigQuery y mayor fiabilidad.
¿Soportas transformaciones con dbt?
Sí. Puedo crear modelos dbt para staging, limpieza, joins, lógica de negocio y tablas analíticas curadas.
¿Puedes trabajar con almacenes de datos o pipelines existentes?
Sí. Puedo mejorar, optimizar, depurar o extender entornos existentes en BigQuery, AWS o ETL.
¿Puedes integrar Power BI u otras herramientas de BI?
Sí. Puedo preparar conjuntos de datos listos para análisis optimizados para Power BI, Looker Studio, Tableau y análisis SQL.
¿Proporcionas monitoreo y manejo de errores?
Sí. Los pipelines de producción incluyen registro, reintentos, alertas y monitoreo para mejorar la fiabilidad y estabilidad operativa.
¿Puedes manejar backfills históricos y grandes conjuntos de datos de API?
Sí. Puedo construir pipelines para sincronización histórica, APIs paginadas y conjuntos de datos a gran escala con estrategias de carga optimizadas.