Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
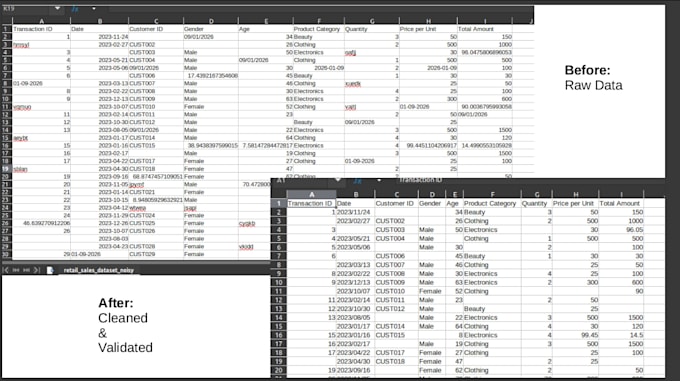
Databridge es un motor de procesamiento de datos local de alto rendimiento diseñado para transformar datos desordenados e inconsistentes en un almacén SQL estructurado. Automatiza el proceso de limpieza de datos, reemplazando cientos de horas manuales con una sola herramienta segura.
Capacidades clave:
Automatización en Python en su mejor versión: Ideal para departamentos de comercio electrónico, finanzas y marketing que manejan informes fragmentados de proveedores.


Tecnología:
Python
•
Otros
Traducción automática
¿Cómo maneja el motor los encabezados no estándar?
Cuenta con un normalizador robusto basado en Regex. Cualquier encabezado como __&&UsER+nAME🥰 se sanitiza automáticamente a user_name. Utiliza coincidencia difusa para encontrar las columnas correctas, incluso si sus nombres o el orden varían entre archivos.
¿Cuáles son las reglas específicas de transformación de datos?
Ofrecemos una biblioteca en crecimiento de tipos: int, float, date, str, además de tipos especializados alpha (solo letras) e identifier. Todos los tipos usan validación estricta y coerción de errores para manejar datos "sucios" de forma segura. Se añaden constantemente más tipos personalizados al motor.
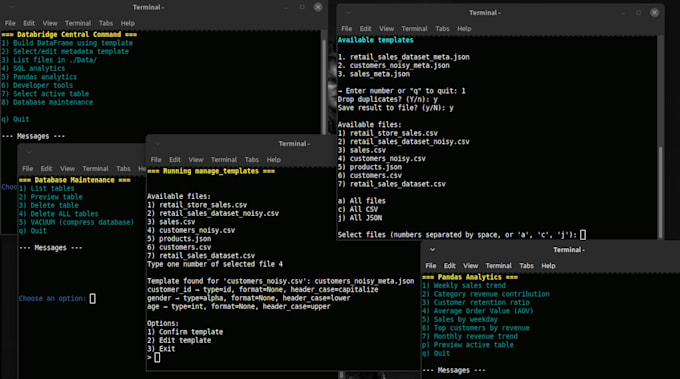
¿Cómo funcionan tus plantillas JSON?
Las plantillas actúan como un contrato. El motor usa regex para encontrar las columnas objetivo sin importar sus nombres o el orden. Luego, convierte estrictamente los datos a los tipos y formatos que elijas (int, float, date). Si falta datos en una fila o no pasa la validación según la plantilla, se ignora de forma segura.
¿Puedo procesar muchos archivos diferentes a la vez?
Sí, en el nivel Enterprise, el "Modo por lotes" te permite indicar una carpeta. El motor recorrerá cada archivo, ignorará los datos irrelevantes según tu plantilla y construirá una base de datos consolidada fila por fila.
¿Cómo gestiono la base de datos de salida?
La herramienta incluye un Servicio de Base de Datos. Puedes cambiar entre tablas activas, eliminar conjuntos de datos antiguos y ejecutar el comando VACUUM para desfragmentar el archivo SQLite y recuperar espacio en disco.
¿Cuáles son los requerimientos del sistema?
Es una herramienta CLI basada en Python. Requiere Python 3.9+ instalado en tu máquina. Todo el procesamiento es local, por lo que el rendimiento depende de tu CPU/RAM, pero el motor está optimizado para operaciones por lotes de alta velocidad.