Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
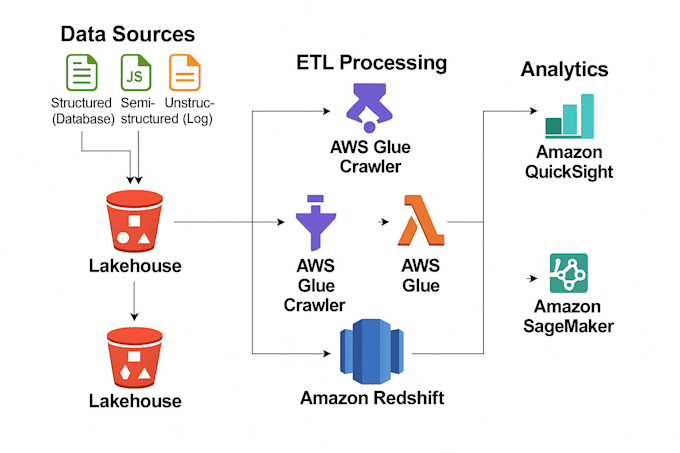
I design and build scalable data pipelines tailored to your business needs. Using Python, PySpark, SQL, and AWS, I automate data ingestion, transformation, and storage to deliver clean, reliable, and analytics-ready data. I perform data quality checks like missing value detection, duplicate removal, format verification, and schema validation to ensure data integrity.
I also create interactive dashboards and reports with Amazon QuickSight and Tableau to help you monitor KPIs and make data-driven decisions easily. Whether you need ETL workflows, data validation, cloud deployment, or reporting solutions, I deliver optimized, scalable systems.
I prioritize clear communication, on-time delivery, and ongoing support to help your data infrastructure evolve with your business. Lets turn your raw data into actionable insights!