Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
India
Ingeniero de datos senior, Spark, Scala, AWS, Airflow, Kafka, Big Data
¿Buscas un Ingeniero de Datos PySpark confiable para construir u optimizar tus pipelines ETL?
Estás en el lugar correcto.
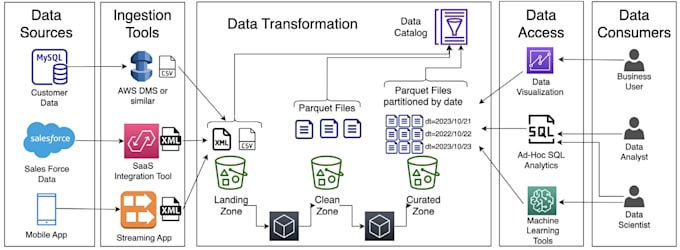
Soy Pankaj, un Ingeniero de Datos con más de 3 años de experiencia en Paytm, donde construí más de 200 pipelines ETL en producción procesando más de 5 TB/día usando PySpark, Airflow, AWS y Kafka.
Este servicio se centra al 100% en ofrecer soluciones PySpark ETL rápidas, escalables y limpias para tu negocio.
Lo que puedo hacer por ti
Por qué elegirme
Tecnologías que uso
¿Tienes un requerimiento personalizado?
Envíame un mensaje en cualquier momento, respondo rápido.
Construyamos algo escalable.

Traducción automática
¿Qué necesitas de mí para empezar?
Acceso a base de datos/API, datos de muestra, lógica SQL o declaración del problema.
¿Puedes conectarte a mi base de datos o API?
Sí — MySQL, PostgreSQL, MongoDB, APIs, S3 y más.
¿Optimizas pipelines existentes?
Sí — me especializo en optimización de tiempo de ejecución y depuración.
¿Puedes integrar servicios de AWS?
Sí — Glue, S3, EMR, Lambda, Athena.
¿Puedes firmar un NDA?
Sí — puedo trabajar bajo NDA si es necesario.