Ejecuta modelos LLaMA localmente en tu propio hardware y desbloquea una IA rápida y privada. Me especializo en desplegar LLaMA LLMs para principiantes y desarrolladores usando llama.cpp, un motor de inferencia ligero en C/C++ que permite inferencia local de alto rendimiento. Obtendrás una configuración completa en Windows y Linux. sin nube, sin tarifas recurrentes y con control total sobre tus modelos de IA.
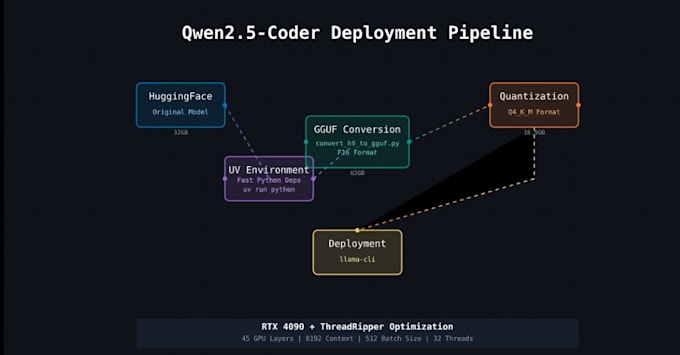
- Instalación local: Instalaré y configuraré los modelos LLaMA (2/3) más recientes o compatibles con GGUF en tu máquina. Ya sea en Windows, Linux o Mac, me encargo de la configuración del entorno, dependencias y la instalación del build o binario de llama.cpp.
- Optimización GPU & CUDA: Con soporte para NVIDIA CUDA, habilitaré la aceleración GPU (y multi-threading) para acelerar la inferencia. Usando las optimizaciones de llama.cpp y la cuantización del modelo (4-bit/8-bit), reduciremos el uso de memoria para que incluso modelos grandes funcionen sin problemas (los modelos cuantizados son mucho más ligeros y mantienen buena precisión).
- Ajuste fino y datos personalizados: En el paquete premium, ajusto tu modelo LLaMA con tu propio conjunto de datos usando adaptadores LoRA (LoRA nos permite adaptar el modelo a tus necesidades entrenando solo los pesos del adaptador).