Explorar las categorías
Explora
Fiverr Pro
Español
$
USD


Traducción automática
¡Deja de gastar dinero en llamadas redundantes a la IA!
La mayoría de las aplicaciones de IA desperdician del 40% al 80% de su presupuesto en llamadas redundantes a LLM. Estoy aquí para ayudarte a detener esa pérdida.
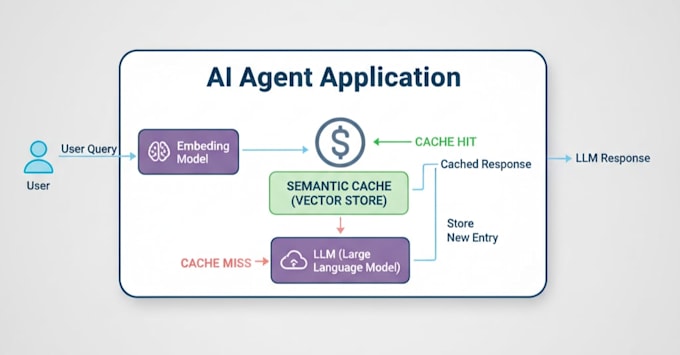
Construiré un cache semántico listo para producción que "recuerda" consultas pasadas y proporciona respuestas al instante, reduciendo tus costos y haciendo que tu app sea increíblemente rápida.
¿Qué es el caching semántico?
El caching estándar es "tonto"; necesita una coincidencia palabra por palabra al 100%. El caching semántico es inteligente. Usando embeddings vectoriales, tu sistema entenderá la intención. Si el usuario A pregunta "¿Cómo está el clima?" y el usuario B pregunta "¿Cuál es el pronóstico?", el sistema sabe que son lo mismo. Proporciona la respuesta almacenada al instante sin hacer llamadas a tu API.
¿Qué incluye este gig?
Code, Scrape, Automate, FullStack Developer for Data and AI
Idiomas
Traducción automática
Traducción automática
¿El caching hará que la IA dé información "vieja" o "incorrecta"?
No si se hace correctamente. Implementamos "Invalidación de cache" y configuraciones de "Tiempo de vida" (TTL). Si tus datos cambian frecuentemente, podemos configurar el cache para que expire cada hora. Si los datos son estáticos, puede durar para siempre. También ajustamos el "Umbral de similitud" para que solo preguntas realmente similares activen el cache.
¿Cuánto dinero realmente voy a ahorrar?
Esto depende de tu "Tasa de aciertos del cache". Para bots de soporte al cliente o FAQs, los usuarios suelen hacer preguntas similares, lo que genera ahorros del 60-90%. Para bots de tareas altamente creativas o únicas, los ahorros suelen estar en torno al 20-30%.
¿Mis datos están seguros?
Totalmente. El cache se aloja en tu infraestructura (o en tu base de datos en la nube preferida). No almaceno tus datos en mis propios servidores.
¿Esto funciona con cualquier LLM?
Sí. Ya sea que uses GPT-4 de OpenAI, Google Gemini 1.5, Claude 3.5, o modelos locales como Llama 3, la capa de caching se sitúa delante de la API, haciendo que sea independiente del proveedor.