Explorar las categorías
Explora
Fiverr Pro
Español
$
USD





Traducción automática
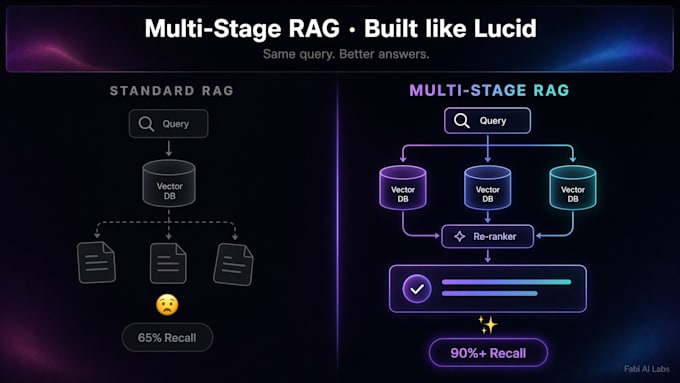
El RAG estándar se queda atascado con preguntas compuestas. Un bot de una sola consulta recupera fragmentos que mencionan "reembolso" y pierde matices — reglas de precios, cláusulas de daño, políticas de pedidos personalizados.
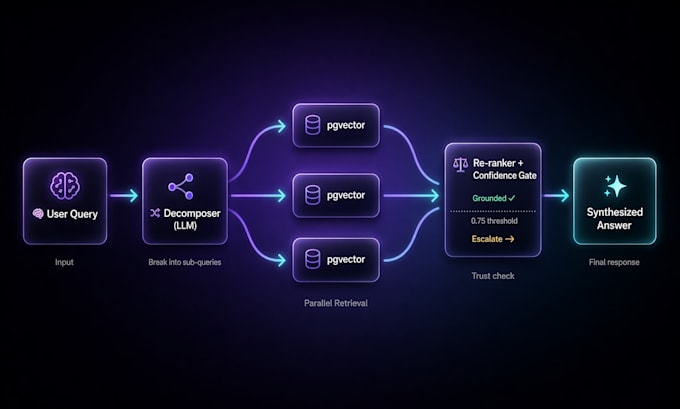
El RAG de múltiples etapas es diferente. Se descompone en sub-consultas, busca en paralelo, re-ranke y sintetiza. La tasa de recuperación sube del 65% al 90%+. Las respuestas permanecen fundamentadas. Las alucinaciones disminuyen.
LO QUE obtienes:
- Descomposición de consultas (el LLM divide preguntas compuestas en búsquedas específicas)
- Embedding hipotético HyDE para recuperación
- Re-ranke + puntuación de confianza antes de generar la respuesta
- 4 salvaguardas: transferencia humana, puerta de incertidumbre, sin gaslighting, transparencia
- Conjunto de evaluación personalizado con calidad de recuperación medible
- Panel de administración para depuración de conversaciones y recuperación (Premium)
STACK: Python/TypeScript, Supabase pgvector, APIs de OpenAI/Anthropic/Gemini, re-ranker personalizado.
POR QUÉ MULTI-ETAPA: el RAG de una sola consulta funciona para FAQs simples. Si tu bot maneja matices de precios o preguntas compuestas, necesitas esto.
Esto es lo que integré en Lucid. Misma arquitectura para tu dominio, ajustada a tu voz.
Envíame tu caso de uso más 10 preguntas difíciles que tu bot actual no pueda responder. Te responderé con el alcance.
AI Developer and Creator of Lucid
Idiomas
Traducción automática
Traducción automática
¿En qué se diferencia el RAG de múltiples etapas del RAG básico?
El RAG básico realiza una búsqueda de vector por pregunta. Para preguntas compuestas, la recuperación de una sola búsqueda es aproximadamente del 65%. El RAG de múltiples etapas descompone la pregunta, busca en paralelo, re-ranke. La recuperación sube al 90%+. Menos alucinaciones, respuestas mejor fundamentadas.
¿Costará esto más que el RAG básico a gran escala?
A menudo menos. La descomposición usa modelos económicos (Gemini Flash a aproximadamente 0.10 dólares por 1 millón de tokens). La respuesta final usa una llamada a un modelo premium. El RAG básico paga premium por cada llamada. Con más de 10k conversaciones al mes, el multi-etapa suele ser un 30-50% más barato.
¿Qué pasa si mis documentos están desordenados o sin estructura?
Se maneja como parte del alcance. Normalizo los documentos durante la ingesta — fragmentación por límites semánticos (no divisiones ingenuas por párrafos), limpieza de boilerplate, adición de metadatos para recuperación basada en filtros. La entrada desordenada es la suposición por defecto, no una excepción.
¿Aún debo traer mis propias claves API?
Sí, igual que en mi gig de Starter Bot. Tú posees las cuentas de OpenAI / Anthropic / Gemini, pagas precios directos sin margen, mantienes control total. Ayudo a elegir la combinación de modelos más rentable para tu volumen de tráfico.