Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniería profesional de Big Data para infraestructura escalable y lista para producción
Ofrezco soluciones prácticas de big data de principio a fin, desde la planificación de la arquitectura hasta el despliegue y la optimización, utilizando herramientas estándar de la industria. Cada solución se adapta a tus objetivos, infraestructura y requisitos de carga de trabajo para garantizar rendimiento, escalabilidad y estabilidad a largo plazo.
Servicios incluidos:
Por qué los clientes eligen este servicio:


Idioma:
Inglés
•
Urdu
Experiencia técnica:
Apache NiFi
•
apache spark
•
hadoop
•
Otros
industria:
Análisis de Datos
Traducción automática
¿Qué tipos de proyectos de big data manejas?
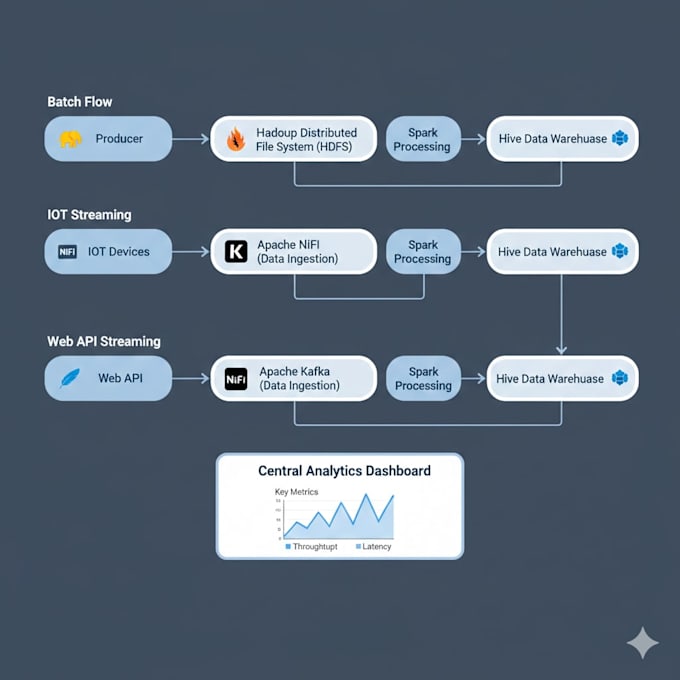
Me encargo de la configuración, implementación, optimización y resolución de problemas en entornos de big data usando Hadoop, Spark, Kafka, Hive, NiFi y herramientas relacionadas, desde sistemas pequeños de prueba de concepto hasta clústeres de producción.
¿Puedes configurar un clúster completo de Hadoop o Spark desde cero?
Sí. Puedo diseñar y desplegar clústeres totalmente funcionales, incluyendo configuración, ajuste de rendimiento y validación para garantizar la estabilidad.
¿Ofreces soporte para pipelines de streaming de datos en tiempo real?
Por supuesto. Construyo pipelines de streaming basados en Kafka e los integro con Spark o NiFi para un procesamiento eficiente de datos en tiempo real.
¿Proporcionas documentación?
Sí. Incluyo documentación clara para ayudarte a entender, gestionar y mantener tu sistema.
¿Cómo empezamos?
Simplemente comparte tus requisitos, detalles de infraestructura y objetivos — yo propondré el mejor plan de implementación.