Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniero, lector beta y traductor de EN a PT, rápido y confiable
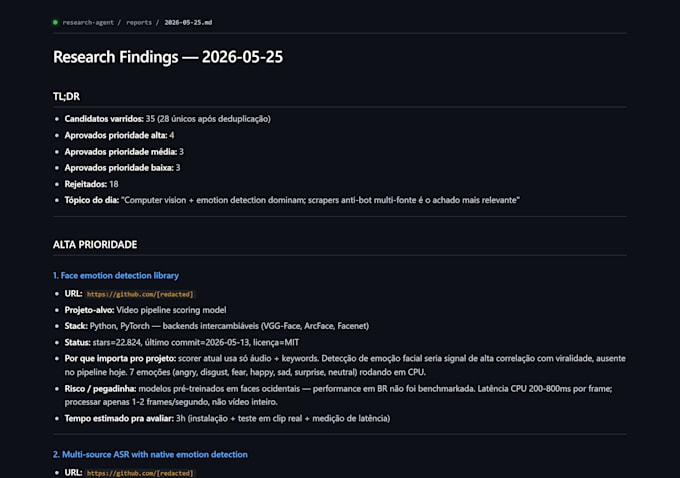
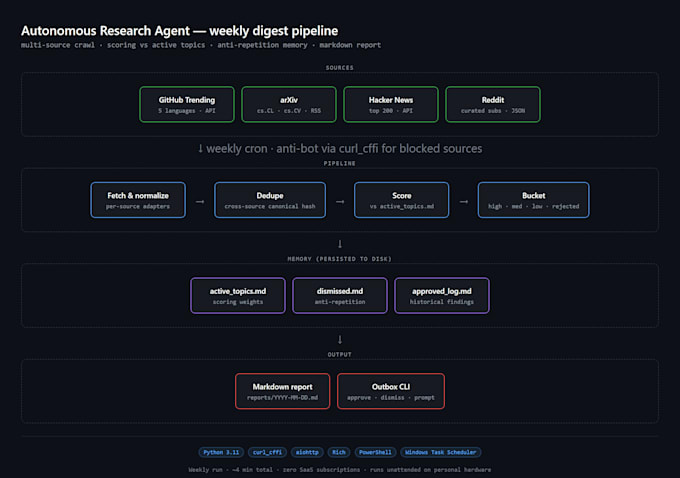
La mayoría de los trabajos de scraping en Fiverr se rompen en cuanto un sitio habilita Cloudflare Bot Management o DataDome. Yo escribo scrapers que NO lo hacen.
Stack que uso:
Objetivos que he scrapeado con éxito:
Lo que entrego:
Nota legal: el scraping es TU responsabilidad. Yo construyo la herramienta; tú aseguras el cumplimiento de ToS, robots.txt y las leyes de tu jurisdicción.


Tecnología:
Python
•
scrapy
•
Selenium
•
Beautiful Soup
•
Playwright
Técnica:
Automatizado
Traducción automática
¿Este scraper funcionará para siempre?
No. Las defensas antibot evolucionan. Los scrapers se rompen cada 3-12 meses. Documentaré CÓMO funciona la elusión para que TÚ puedas adaptarte o contratarme para parches.
¿Proporcionas proxies?
No. Tú compras proxies (recomendado Decodo o BrightData residenciales - 5-8$/GB). Yo configuro la lógica de rotación en el scraper.
¿Puedes scrapeando Instagram / Facebook / LinkedIn?
No. Tienen equipos legales agresivos y enforcement activo. Rechazo estas solicitudes. Otros sitios antibot están bien.