Explorar las categorías
Explora
Fiverr Pro
Español
$
USD

Traducción automática
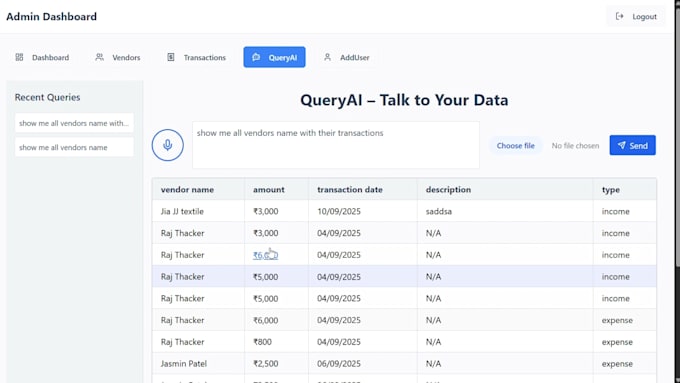
¿Necesitas automatizar la extracción de información de documentos en lugar de hacer trabajo manual de copiar y pegar? Creo soluciones de automatización basadas en Python que procesan archivos rápida, precisa y a gran escala.
Tengo experiencia creando flujos de trabajo para procesamiento de documentos en informes financieros, manejo de facturas, automatización de hojas de trabajo y pipelines de datos estructurados.
Lo que puedo ayudarte a hacer:
Extraer datos de facturas, recibos, formularios y documentos financieros
Procesar tablas e información estructurada de archivos complejos
Gestionar documentos de varias páginas y archivos escaneados usando OCR
Convertir la información extraída en formatos JSON, CSV, Excel o listos para bases de datos
Crear scripts de automatización o flujos de trabajo basados en API para integrarlos en sistemas existentes
Pila tecnológica: Python · pdfplumber · PyMuPDF · OCR · FastAPI · SQL
Los entregables incluyen código limpio, instrucciones de configuración, documentación y muestras de resultados para pruebas.
Por favor, envíame un mensaje con un archivo de muestra y el formato de salida esperado antes de ordenar para confirmar el alcance y la viabilidad.
Python Backend Developer with FastAPI REST APIs and AI Integration
Idiomas
Traducción automática
Traducción automática
¿Puedes manejar archivos PDF escaneados?
Sí, uso OCR (Tesseract/AWS Textract) para documentos escaneados.
¿En qué formato será la salida?
JSON, CSV o directamente en tu base de datos — tú eliges.
¿Puedes procesar PDFs automáticamente en un horario programado?
Sí, puedo crear un pipeline automatizado en el paquete Standard o Premium.