Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Sobre este servicio
Me especializo en construir sistemas multimodales de reconocimiento de voz y emociones combinando modalidades de audio y texto para mejorar el rendimiento y la precisión.
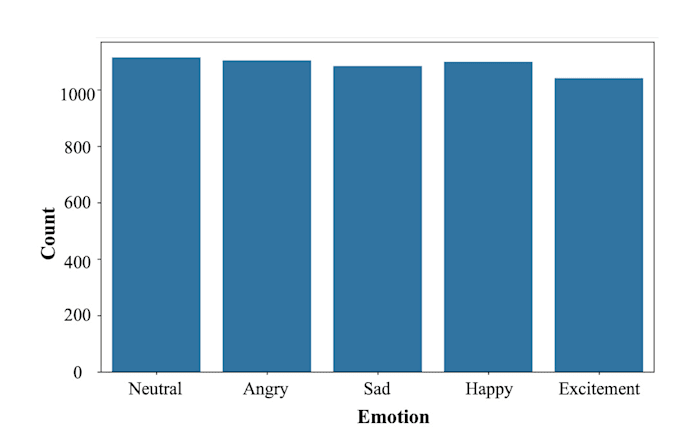
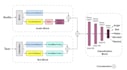
Con experiencia práctica trabajando en conjuntos de datos complejos como IEMOCAP y MELD, he desarrollado modelos híbridos personalizados usando Bi-LSTM y CNN, logrando hasta 85% de precisión en el conjunto de datos IEMOCAP. También estoy explorando activamente Word2Vec y arquitecturas basadas en Transformer para mejorar la comprensión contextual en el reconocimiento de voz.
Puedes consultar mis proyectos y artículos de investigación vinculados abajo para más detalles.
Lo que ofrezco:
No dudes en enviarme un mensaje antes de hacer tu pedido para discutir tus necesidades específicas.

Experiencia:
Clasificación
•
Voz y audio
•
Análisis predictivo
Lenguaje de programación:
Python
•
Colab
API:
Otros
Herramientas:
Jupyter Notebook
•
Amazon SageMaker
•
Colab
Marcos:
Scikit-learn
•
keras
•
PyTorch
•
Panda
•
TensorFlow