Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Convierte tus datos en una herramienta poderosa para la toma de decisiones con un Data Scientist certificado por IBM.
No solo escribo código; construyo modelos de Machine Learning de alto rendimiento diseñados para precisión y fiabilidad. Con formación en Ingeniería y capacitación especializada de IBM, combino la complejidad de los datos sin procesar con insights accionables para negocios o entornos clínicos.
Lo que obtendrás:
¿Por qué elegirme? Aplico una mentalidad de ingeniería a la ciencia de datos, enfocándome en precisión, estabilidad del modelo y rendimiento en el mundo real. Ya sea en salud, finanzas o datos empresariales, entrego resultados en los que puedes confiar.
Listo para desbloquear el poder de tus datos



Lenguaje de programación:
Python
•
SQL
Marcos:
Scikit-learn
•
Panda
API:
Microsoft Computer Vision AI
Herramientas:
Jupyter Notebook
•
MLflow
Traducción automática
¿Qué necesitas de mí para empezar?
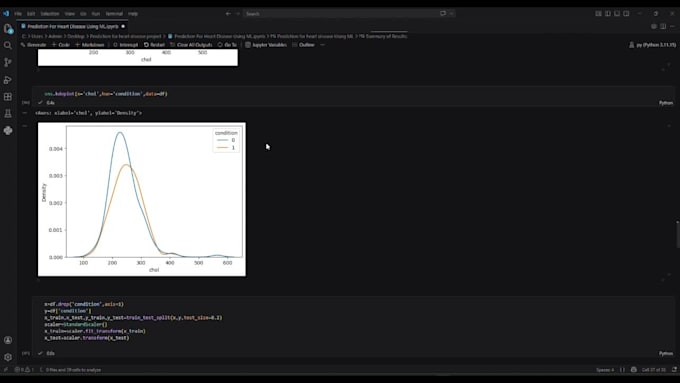
Necesito tu conjunto de datos (CSV, Excel, SQL o acceso a API) y una descripción clara de tu objetivo. ¿Estás intentando predecir un resultado específico o solo necesitas un análisis exploratorio? Cuanto más contexto brindes sobre las características, mejores serán los resultados.
¿Qué herramientas y bibliotecas utilizas?
Trabajo principalmente en Python usando la pila estándar de la industria: Pandas y NumPy para manejo de datos, Matplotlib y Seaborn para visualización, y Scikit-Learn, XGBoost o LightGBM para Machine Learning. Todo el trabajo se entrega en notebooks de Jupyter organizados.
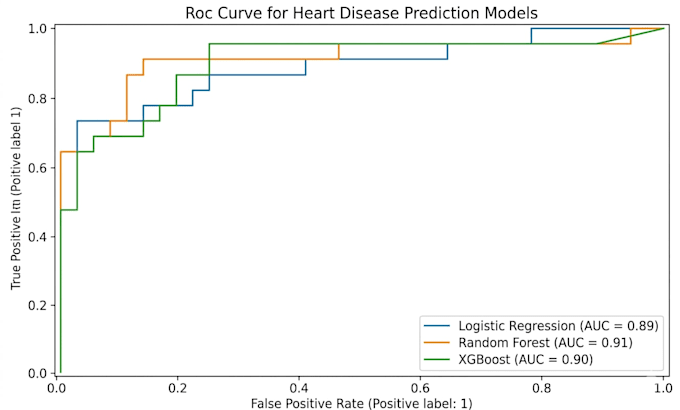
¿Puedes garantizar una precisión específica del modelo?
En ciencia de datos, la precisión depende completamente de la calidad y volumen de tus datos. Sin embargo, garantizo un enfoque riguroso de ingeniería—usando GridSearchCV y validación cruzada—para asegurar que encontremos el modelo con mejor rendimiento posible para tu conjunto de datos específico.
¿Podré entender y ejecutar el código yo mismo?
Por supuesto. Proporciono código limpio y comentado que sigue las mejores prácticas. Mis paquetes Standard y Premium también incluyen un informe técnico profesional en PDF que explica la metodología y los resultados en un lenguaje sencillo, para que puedas presentar los hallazgos a partes interesadas no técnicas.
¿Puedes trabajar con datos sensibles o médicos?
Sí. Con mi formación en Ingeniería Biomédica, conozco la importancia de la privacidad de los datos y la precisión clínica. Sigo estrictos principios éticos profesionales para garantizar que tus datos permanezcan confidenciales y seguros durante todo el proceso.