Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Ingeniero de Datos, AWS, Apache Airflow, Spark, PostgreSQL, ETL
¿Estás ahogado en datos sin una forma confiable de procesarlos?
Construyo canalizaciones de datos de grado producción que se ejecutan automáticamente, escalan con tus datos y nunca fallan silenciosamente. Sin scripts enredados. Sin pasos manuales. Solo datos limpios y confiables exactamente donde los necesitas.
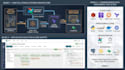
Lo que construyo

Traducción automática
P: ¿Qué información necesita para comenzar?
A: Tu fuente de datos (S3, API, base de datos, CSV), tu destino final, requisitos de transformación y con qué frecuencia debe ejecutarse la canalización.
¿Puedes trabajar con mi infraestructura existente?
A: Sí. Envíame los detalles y evaluaré la compatibilidad antes de comenzar.
P: ¿Necesito una cuenta de AWS?
A: Para trabajos basados en AWS, sí — necesitarás tu propia cuenta. Puedo guiarte en la configuración si es necesario.
P: ¿Seré dueño del código?
A: Completamente. Todo el código fuente se te entrega al finalizar.
P: ¿Puedes manejar grandes conjuntos de datos?
A: Sí. Uso PySpark y EMR en EKS específicamente porque están diseñados para procesamiento de datos a gran escala.
¿Qué pasa si algo se rompe después de la entrega?
A: Ofrezco soporte post-entrega. Envíame un mensaje y lo solucionaré.


