Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Automatización, Web scraping Django, Flask, desarrollo web frontend InstagramAnalyst
Nivel 1
Ha cumplido determinados criterios de rendimiento y muestra un gran potencial en la plataforma.
Hola,
¿Necesitas extraer datos de sitios web de forma rápida y limpia? Creo scrapers personalizados en Python usando BeautifulSoup, Selenium, Playwright y Scrapy para una extracción de datos precisa y automatizada desde cualquier sitio público.
Ofrezco servicios expertos de scraping web y extracción de datos en Python usando herramientas estándar de la industria como:
️ Herramientas de scraping que utilizo:
Características y resultados:
Sólo hago scraping de fuentes de datos públicas y legalmente accesibles.
Contáctame antes de ordenar para discutir tu caso de uso. Estoy listo para ayudarte a automatizar y extraer los datos web que necesitas.
almohid

Traducción automática
¿Qué es el web scraping y cómo puede beneficiar a mi negocio?
El scraping web es la extracción automatizada de datos de sitios web. Permite a las empresas recopilar datos valiosos y estructurados para investigación de mercado, análisis de competidores, monitoreo de precios, generación de leads, agregación de datos de productos y seguimiento de tendencias, todo sin esfuerzo manual.
¿Qué tipos de sitios web puedes scrapear con Python?
Trabajo con una amplia variedad de sitios web, incluyendo tiendas de comercio electrónico, portales de empleo, listados inmobiliarios, directorios de negocios locales, portales de noticias, bases de datos académicas y más. *Nota: Siempre verifica los permisos del sitio antes de hacer scraping.
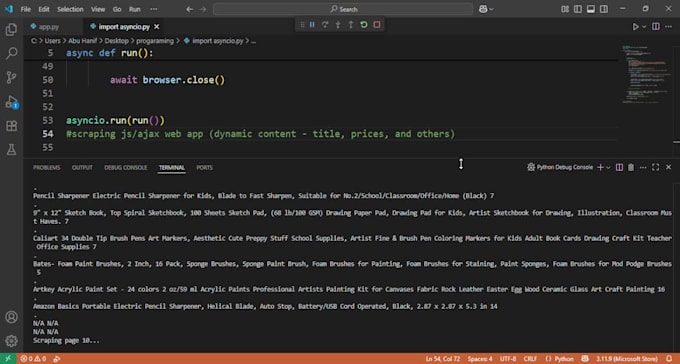
¿Puedes scrapear sitios que usan JavaScript pesado o carga dinámica?
¡Por supuesto! Usando Playwright y Selenium, manejo páginas web complejas con carga dinámica mediante AJAX, desplazamiento infinito u otros elementos impulsados por JavaScript, asegurando que no se pierda ningún dato.
¿Cómo gestionas sitios que requieren inicio de sesión o autenticación de sesión?
Automatizo procesos de inicio de sesión seguros usando Playwright o Selenium, gestionando cookies y tokens de sesión para extraer datos detrás de muros de inicio de sesión, cumpliendo completamente con los términos y condiciones del sitio.
¿En qué formatos puedo recibir mis datos scrapados?
Entrego datos limpios y validados en formatos como CSV, Excel, JSON, XML, bases de datos SQL o Google Sheets, adaptados a tu flujo de trabajo o necesidades de integración de sistemas.
¿Proporcionas los scripts de scraping y el código de automatización?
¡Sí! A pedido, comparto scripts en Python totalmente comentados y reutilizables, construidos con Playwright, Selenium o Scrapy, que te permiten ejecutar o personalizar el scraper de forma independiente.
¿Puedes configurar trabajos de scraping programados y automáticos?
Definitivamente. Configuro trabajos cron, funciones en la nube o scrapers sin servidor para que se ejecuten automáticamente en intervalos personalizados —diarios, semanales o mensuales— para una actualización continua de datos.
¿Cómo gestionas las protecciones anti-scraping y detección de bots?
Implemento técnicas avanzadas incluyendo rotación de user-agent, uso de proxy, modos de navegador stealth (especialmente con Playwright), limitación de solicitudes y manejo de CAPTCHA (donde esté permitido) para sortear medidas anti-bot de forma ética.
¿Qué rapidez puedo esperar para recibir mis datos scrapados?
El tiempo de entrega depende de la complejidad: tareas simples de scraping suelen tomar de 1 a 3 días; proyectos de crawling a gran escala o con múltiples páginas toman de 3 a 7 días. Ofrezco plazos claros y transparentes antes de comenzar.