Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Bangladesh
Acerca de mí
¿Estás buscando construir un modelo de aprendizaje auto supervisado (SSL) y descubrir clústeres significativos en tus datos?
- ¡Estás en el lugar correcto! Soy un experto en Deep Learning con experiencia práctica en SSL, clustering y evaluación de tareas downstream.
Puedo trabajar con una variedad de conjuntos de datos de imágenes, incluyendo:
¿Por qué elegir mi servicio?
Lo que entrego:
¡Dale vida a tus datos! Envíame un mensaje antes de ordenar para asegurarnos de entender completamente los requisitos de tu proyecto.



Experiencia:
Procesamiento de imágenes
•
Clasificación
•
agrupación
Lenguaje de programación:
Python
•
Colab
•
Otros
Herramientas:
Jupyter Notebook
•
opencv
•
Colab
•
PyTorch
Marcos:
PyTorch
•
Panda
•
Otros
Traducción automática
¿Con qué tipos de conjuntos de datos puedes trabajar?
Puedo trabajar con cualquier tipo de conjunto de datos de imágenes, incluyendo imágenes médicas, satelitales, de productos o conjuntos de datos personales/personalizados.
¿Necesito proporcionar un conjunto de datos?
Sí. si quieres que el modelo se entrene con tus datos (productos, caras, documentos, etc.), debes proporcionar las imágenes. Si no tienes un conjunto de datos, puedo ayudarte a recopilar o conseguir uno por un costo adicional. ¡Escríbeme primero!
¿Necesito datos etiquetados?
No, el aprendizaje auto supervisado no requiere datos etiquetados. Sin embargo, puede ser necesario si quieres evaluación en una tarea downstream (paquetes Estándar y Premium).
¿Existen limitaciones en el tamaño del conjunto de datos?
Normalmente trabajo con conjuntos de datos que caben en la memoria GPU disponible, como Colab y Kaggle GPU. Para conjuntos de datos muy grandes, podemos usar estrategias como muestreo, batching o procesamiento distribuido.
¿Qué modelos de deep learning utilizas?
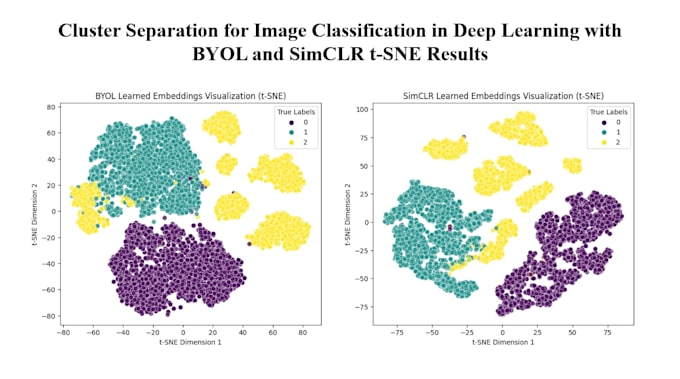
Utilizo modelos de aprendizaje auto supervisado de última generación como SimCLR, BYOL, Barlow Twins.
¿Podré usar el modelo fácilmente?
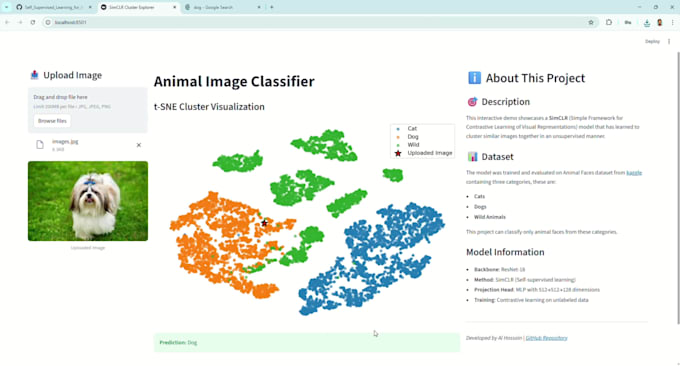
¡Exactamente! Para el paquete Premium, proporciono una aplicación web Streamlit fácil de usar para explorar clústeres y probar tareas downstream de forma interactiva.
¿Puedes evaluar el rendimiento del modelo?
Sí, proporciono métricas de evaluación detalladas en tareas downstream, incluyendo precisión, pérdida y visualizaciones de clústeres.
¿Se garantiza la confidencialidad?
Sí, completamente. Tus datos y detalles del proyecto se mantienen estrictamente confidenciales.