Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
¿Buscas transformar texto en bruto, transcripciones o datos de encuestas en información lista para publicar? ¡Estás en el lugar correcto!
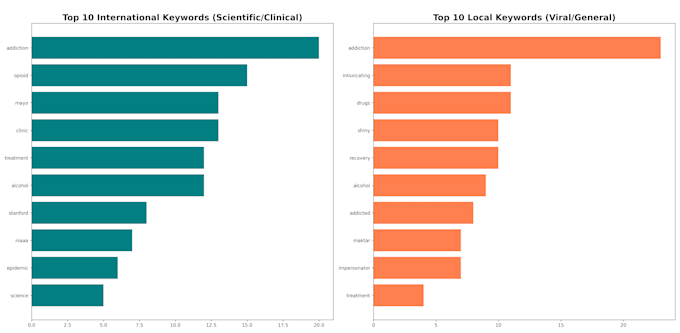
Como Analista de Datos Computacionales, construyo pipelines sólidos de Procesamiento de Lenguaje Natural (PLN) en Python para descubrir patrones lingüísticos ocultos y conocimientos estadísticos a partir de conjuntos de datos textuales no estructurados. Ya sea trabajando con narrativas de investigación, datos de salud pública o tendencias en redes sociales, garantizo el máximo valor empírico.
Lo que ofrece este servicio:
¿Por qué elegirme? Respaldado por una lógica de ingeniería sólida, asegurando que tus datos sean matemáticamente precisos y adaptados para cumplir con los estándares académicos o de presentación más altos.
¡Por favor, envíame un mensaje con una descripción de tu conjunto de datos antes de hacer el pedido!

Lenguaje de programación:
Python
Marcos:
Scikit-learn
•
PyTorch
•
Panda
API:
Google Cloud Vision API
Herramientas:
Otros
Traducción automática
¿Tu pipeline de NLP puede manejar traducción de texto multilingüe o regional?
¡Sí! Puedo implementar capas de mapeo de traducción cruz-lingüística dentro del pipeline de Python antes de realizar análisis textual. Esto asegura que las nuances localizadas se capturen y estructuren con precisión sin perder el valor semántico nativo.