Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Analista de datos, ingeniero de datos en la nube y experto en data warehouse
Nivel 1
Ha cumplido determinados criterios de rendimiento y muestra un gran potencial en la plataforma.
¿Buscas una solución confiable de pipeline de datos que mantenga los análisis actualizados y precisos?
Implementaré tuberías modernas de ingeniería de datos y almacenes de datos en Redshift, Google BigQuery, ClickHouse y Postgres.
Pipeline ETL/ELT por lotes y arquitecturas de streaming en tiempo real, asegurando flujos de datos confiables, automatizados y escalables para análisis y modelos de IA/LLM.
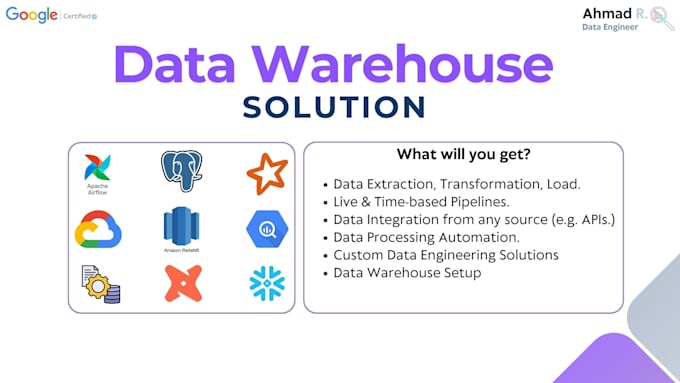
Lo que obtienes:
Mi stack:
Por qué elegirme:
Ingeniero de datos con más de 7 años de experiencia. Me especializo en Redshift, Bigquery, PostgreSQL y arquitecturas personalizadas de almacenes de datos.


Traducción automática
¿Cuál es la diferencia entre pipelines ETL y ELT?
ETL extrae, transforma y luego carga los datos; ELT carga los datos en bruto y luego los transforma en el almacén (común en BigQuery). Podemos implementar cualquiera según tus necesidades.
¿Cuál almacén es mejor para mí?
Redshift funciona mejor para cargas de trabajo analíticas grandes en AWS. BigQuery es un almacén sin servidor en GCP para consultas rápidas y escalables. PostgreSQL es ideal para datos moderados y consultas SQL complejas. ClickHouse destaca en OLAP de alta velocidad y análisis en tiempo real. La elección depende de la escala de tus datos y tu caso de uso.
¿Puedes manejar datos en streaming?
Sí, construyo pipelines en tiempo real usando Kafka, Kinesis o GCP Pub/Sub. El streaming ETL está incluido en el paquete Premium para flujos de datos actualizados.
¿Qué necesitas de mí para empezar?
Por favor, proporciona detalles de tus fuentes de datos (tipo, acceso), almacén deseado, datos o esquema de muestra y objetivos del proyecto (informes, uso de ML). Esto ayuda a personalizar la solución.
¿Cómo usas IA en el pipeline?
Utilizo herramientas de IA para automatizar partes del flujo de trabajo, por ejemplo, usando GPT para redactar código de transformación o inferir esquema de datos, y aplicando modelos BigQuery ML/Redshift ML mediante SQL para funciones predictivas (donde sea relevante).