Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
¡Hagamos que el machine learning funcione para tus objetivos!
Sobre mí
¡Hola! Soy Sivanandham, un Especialista en Machine Learning con experiencia comprobada en pronósticos financieros, predicción del mercado de valores y automatización basada en datos. Con más de 2 años de experiencia práctica en Inteligencia Artificial, Machine Learning, Análisis de Datos, Ciencia de Datos y sistemas de IA.
He entregado más de 25 proyectos reales de ML que realmente resolvieron problemas de negocio, no solo demos académicas.
Servicios que ofrezco:
Desarrollo de modelos ML: Clasificación, Regresión
Pasos en la pipeline: Ingesta de datos, Limpieza y preprocesamiento de datos, Ingeniería de características, Entrenamiento de modelos, Ajuste de hiperparámetros, Validación y predicción
Entrenamiento y evaluación de modelos: Precisión, F1-Score, ROC-AUC
Optimización de modelos: Métricas de evaluación, GridSearchCV
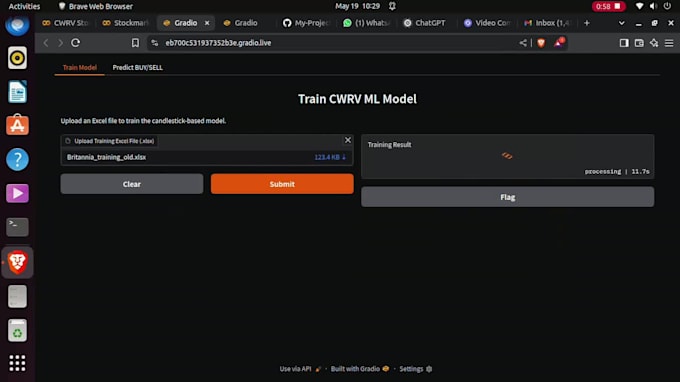
Despliegue de modelos: aplicaciones basadas en Gradio, despliegue local
Herramientas y tecnologías:
Lenguajes y librerías: Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit-learn
Algoritmos de ML: Árboles de decisión, Máquina de vectores de soporte (SVM), Regresión logística/lineal, Gradient Boosting, Validación cruzada, Grid Search
Control de versiones: GitHub
Consejo: Antes de hacer un pedido, envíame un mensaje con tu conjunto de datos, objetivos y expectativas para que pueda ofrecerte el plan y el plazo adecuados.




Lenguaje de programación:
Python
•
Colab
Marcos:
Scikit-learn
•
PyTorch
•
Panda
API:
Google Cloud Vision API
Herramientas:
Jupyter Notebook
•
opencv
•
Excel
•
MLflow
•
Colab
Traducción automática
¿Puedes trabajar con mi conjunto de datos en bruto, o debe estar limpio?
Sí, puedo trabajar con datos en bruto. Ofrezco limpieza completa de datos (ETL), preprocesamiento y transformación para que tu conjunto de datos esté listo para ML, incluyendo manejo de valores faltantes, outliers y problemas de formato.
¿Qué entregables recibiré?
Recibirás código en Python (limpio y bien comentado), visualizaciones de rendimiento (matriz de confusión, curva ROC, importancia de características), explicación del modelo y archivos listos para despliegue.
¿Cómo aseguras que el modelo tenga buen rendimiento?
Utilizo técnicas comprobadas como validación cruzada, división entrenamiento-prueba, análisis de sesgo-varianza y ajuste de hiperparámetros (GridSearchCV) para construir modelos optimizados y robustos.
¿Cómo elijo entre los paquetes Básico, Estándar y Avanzado?
● Básico es ideal para casos simples o aprendizaje para principiantes. ● Estándar incluye preprocesamiento completo, manejo de desequilibrios y ajuste, perfecto para pequeñas empresas. ● Avanzado ofrece modelos listos para producción, comparación de múltiples algoritmos y interfaz de usuario, ideal para profesionales y proyectos de investigación.
¿Mis datos se mantendrán privados?
Por supuesto. Tus datos se tratan como confidenciales y nunca se compartirán ni reutilizarán.
¿Cómo sé que tu servicio es confiable?
Con más de 25 proyectos de ML del mundo real, formación avanzada (certificación en IA de 6 meses de Novi Tech) y resultados comprobados en negocios (por ejemplo, crecimiento del 2166% usando insights de ML), entrego modelos estructurados, explicables e impactantes, adaptados a tus objetivos.
¿Puedes proporcionar documentación o explicación estilo notebook?
Sí. Puedo entregar el proyecto en formato Jupyter Notebook o Google Colab con explicaciones paso a paso, comentarios y salidas visuales para mejor comprensión y reutilización.
¿Qué tamaño de conjunto de datos puedes manejar?
Puedo trabajar con conjuntos de datos pequeños a moderados de manera eficiente, y se pueden hacer ofertas personalizadas para garantizar un rendimiento optimizado usando técnicas eficientes de manejo de memoria.
¿Qué servicios específicos de ciencia de datos ofreces?
Ofrezco una variedad de servicios incluyendo limpieza y preprocesamiento de datos, análisis exploratorio, modelado predictivo, ajuste fino, desarrollo de algoritmos de machine learning, visualización de datos y conocimientos accionables.
¿Cómo garantizan la confidencialidad y seguridad de mis datos?
Tus datos se manejan con estricta confidencialidad. Todos los datos sensibles se procesan en entornos seguros y no se subirán en línea ni se procesarán usando plataformas en línea: tus datos solo son accesibles para ti y el Jupyter Notebook que corre en mi laptop.