Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
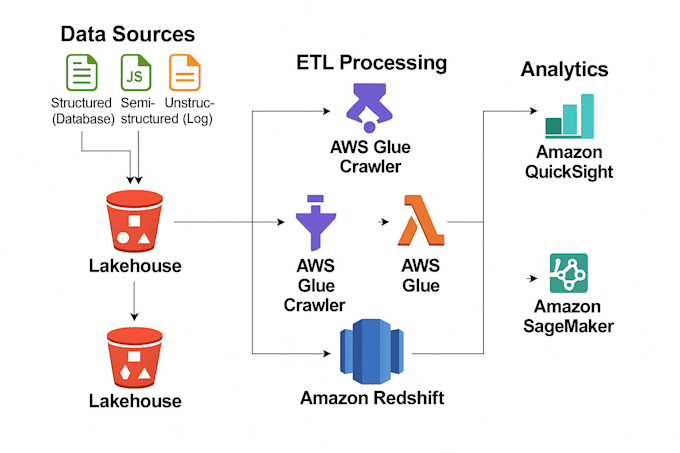
Diseño y construyo pipelines de datos escalables adaptados a las necesidades de tu negocio. Usando Python, PySpark, SQL y AWS, automatizo la ingesta, transformación y almacenamiento de datos para entregar información limpia, confiable y lista para análisis. Realizo verificaciones de calidad de datos como detección de valores faltantes, eliminación de duplicados, verificación de formato y validación de esquemas para garantizar la integridad de los datos.
También creo dashboards interactivos e informes con Amazon QuickSight y Tableau para ayudarte a monitorear KPIs y tomar decisiones basadas en datos fácilmente. Ya sea que necesites flujos de trabajo ETL, validación de datos, despliegue en la nube o soluciones de reporte, entrego sistemas optimizados y escalables.
Prioritizo una comunicación clara, entregas a tiempo y soporte continuo para que tu infraestructura de datos evolucione junto con tu negocio. ¡Convirtamos tus datos en insights accionables!