Explorar las categorías
Explora
Fiverr Pro
Español
$
USD
Construyo sistemas de IA que gestionan las operaciones de tu negocio
Nivel 2
Ha cumplido con los criterios de alto rendimiento y tiene un historial comprobado de cumplimiento de las expectativas de los clientes.
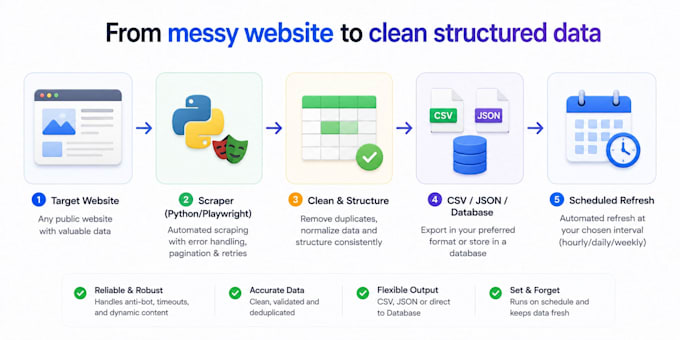
¿Necesitas datos de un sitio web pero copiarlo a mano te está quitando mucho tiempo? Creo scrapers en Python y bots de automatización de navegador que extraen datos limpios y estructurados de forma automática.
Lo que creo:
Herramientas: Python, Scrapy, BeautifulSoup, Playwright, Selenium, Requests, curl_cffi, Pandas, servicios de proxy (Bright Data, ScraperAPI, ZenRows).
Entrego código listo para usar con instrucciones claras, para que puedas volver a ejecutarlo en cualquier momento, además de 7 días de correcciones gratuitas.
Envíame un mensaje con el sitio objetivo y los campos que necesitas.

Tecnología:
Python
•
scrapy
•
Selenium
•
Beautiful Soup
•
Playwright
Técnica:
Automatizado
Traducción automática
¿Esto es legal / cumple con las normas?
Sigo los TOS del sitio web, robots.txt y leyes de privacidad. No recojo datos personales sensibles ni evado muros de pago. Solo datos públicos y comerciales.
¿Puedes manejar sitios dinámicos, scroll infinito o páginas renderizadas con JS?
Sí, usando Playwright/Selenium/Scrapy con paginación, desplazamiento, condiciones de espera y resistencia a cambios en el diseño.
Qué necesitas para empezar?
URL(s) del sitio, campos a extraer, página(s) de muestra, volumen esperado, formato de salida (CSV/Excel/JSON/Sheets/DB) y credenciales de login/prueba si se requieren.
¿Qué pasa con captchas, límites de tasa o bloqueos?
Utilizo proxies rotativos, user-agents, retrocesos/reintentos y throttling inteligente. Si hay anti-bot pesado, propongo alternativas seguras o cobertura parcial.
¿Qué formatos puedes entregar?
CSV, Excel, JSON, Google Sheets o carga directa a SQLite/PostgreSQL/MySQL. También puedo ofrecer un esquema simple listo para ETL.
¿Incluyes limpieza y validación de datos?
Sí, deduplicación, recorte, conversión de tipos, análisis con regex y verificaciones de integridad/unicidad cuando sea aplicable.
¿Recibiré el script de scraping o solo los datos?
Entrega básica/estándar con datos. La versión Premium incluye código en Python y guía de configuración. La propiedad del script pasa a ti.
¿Puedes configurar scraping programado / monitoreo?
Sí, ejecuciones diarias/semanales con actualizaciones por email/Sheets. La versión Premium puede incluir despliegue en Docker o un programador en la nube ligero.
¿Puedes extraer datos de cualquier sitio web que quiera?
Puedo extraer datos de la mayoría de sitios web accesibles públicamente. Algunos sitios tienen términos de servicio estrictos o requieren inicio de sesión para datos privados, lo cual señalaré antes de comenzar. Solo extraigo datos públicos y sigo los límites legales. Envíame la URL del objetivo y confirmaré la viabilidad antes de que hagas tu pedido.