Explorar las categorías
Explora
Fiverr Pro
Español
$
USD

Level 2

Traducción automática
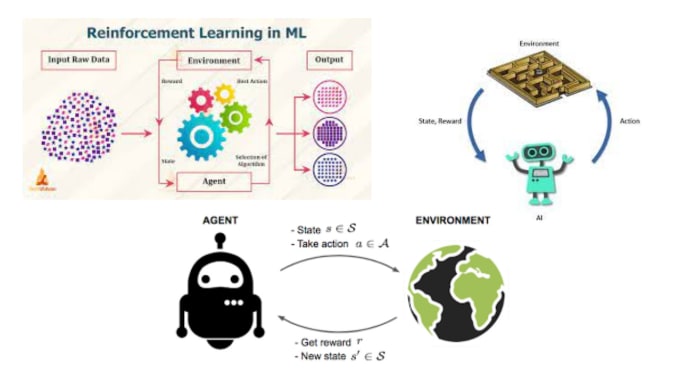
Agentes de Policy Gradient: Aprovecha el poder de los métodos de Policy Gradient, que permiten a tus agentes de IA aprender políticas óptimas mediante ascenso de gradiente. Me especializo en diseñar, entrenar y ajustar estos agentes para diversas aplicaciones.
Deep Deterministic Policy Gradient (DDPG): Aprovecha DDPG, un algoritmo de vanguardia para espacios de acción continuos. Puedo ayudarte a implementar y optimizar agentes DDPG para tareas como robótica, sistemas de control y vehículos autónomos.
Proximal Policy Optimization (PPO): PPO es conocido por su estabilidad y robustez en RL. Puedo guiarte en el proceso de usar PPO para entrenar agentes en entornos complejos, asegurando una rápida convergencia y resultados de alto rendimiento.
Arquitecturas Actor-Critic: Emplea métodos Actor-Critic para espacios de acción discretos y continuos. Benefíciate de la sinergia entre la aproximación de funciones de valor y la optimización de políticas para resolver problemas desafiantes de RL.
Integración de redes neuronales: Aprovecha el poder de las redes neuronales profundas para mejorar las capacidades de aprendizaje de tus agentes de RL, asegurando que se adapten y destaquen en entornos complejos.
optimized AI Models
Level 2
Idiomas
Traducción automática
